- Ask a related questionWhat is a related question?A related question is a question created from another question. When the related question is created, it will be automatically linked to the original question.
HI,
Used SDK8.2
Problem phenomenon:
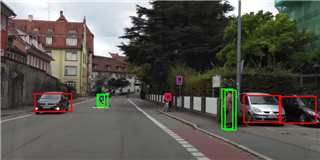
Using the 8bit method to quantify the yolox model will cause the large target detection position becomes smaller
Experimental record:
I have trained a variety of yolox models, and there will be a similar problem that the large target detection position becomes smaller to varying degrees.
1. Using 16bit quantization can be improved, but the project cannot accept the increase in inference time too much.
2. Using the Troubleshooting Guide for Accuracy/Functional Issues provided by TI to investigate, where is the specific problem that has not been located?
3. Try to use the method suggested by TIDL-RT: Quantization, and the experimental conclusion also shows that the large target detection position becomes smaller. (excluding the use of QAT)
Hope TI can give better suggestions or solutions.
img-8bit:

16bit