Hello TI,
We are trying to create a custom kernel for image rotation using MMALIB_linalg function. The sdk version we are using is 08_02_00_05 and the MMALIB version we are using is 02_03_00_04.
To achieve rotation, first the image matrix is transposed and then multiplied with a flipped identity matrix. This can achieve 90-degree rotations.
We started working from vision_apps/apps/basic_demos/app_c7x_kernel as a base and built our code from there onward. The edited custom code for target kernel is attached below for your reference.
We are facing an error while running this app in EVM. Its memory related issue.
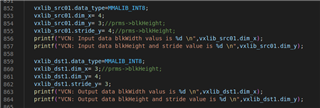
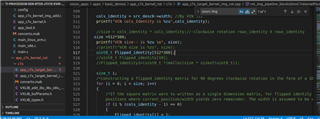
We were getting compilation error when we configure "L2dmemory" to "L2RAM_C7x_1". So we configured "L2dmemory" to "DDR_C7x_1" in "ti-processor-sdk-rtos-j721e-evm-08_02_00_05_lin_evm/vision_apps/platform/j721e/rtos/c7x_1/j721e_linker_freertos.cmd" file. Below screenshot for your reference.
Now the compilation is fine and getting run time error ie, application is getting stuck in the middle and getting garbage values.
Suppose my image size is 512x512 I need to create one flipped identity matrix with size of 512x512.
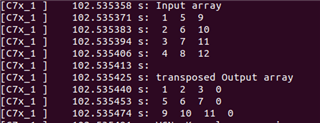
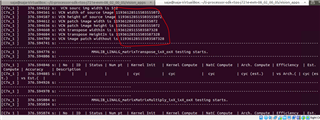
Currently I am hardcoding the values for testing so if my array size is more than 512x200 (>100kb) am reading garbage values for the other parameters in the code. Below screenshot with array size of 320x320 it works fine but still execution stuck.
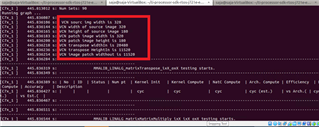
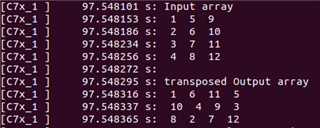
below screenshot with array size of 512x300. Am getting garbage value.
 app_c7x_target_kernel_img_rot.cpp
app_c7x_target_kernel_img_rot.cpp
I have attached the cpp file for your reference. Please look into the "static vx_status rot_img_pipeline_blocks" function. Line number 440.
The execution stuck at line number 564.
Please let me know if you need any other information.