



Hi there,
We are currently using QAT to fine-tune a yolov5s model using edgeai-torchvision repository(https://github.com/TexasInstruments/edgeai-torchvision/blob/master/docs/pixel2pixel/Quantization.md)
The following is what we've tried so far,
- Trained a yolov5s
- Wrap the model with xnn module
- load the checkpoint
But the training crashed at the first epoch because of NAN as you can see in the image below,
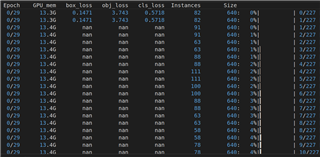
And then we changed the order of checkpoint loading and model wrapping,
- Trained a yolov5s
- load the checkpoint
- Wrap the model with xnn module
The model training runs well and can converge at the end.
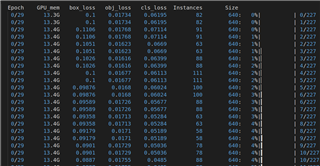
Questions:
- Which order of checkpoint loading and model wrapping is correct?
- We met the accuracy drop problem after we compiled the QAT model into TIDL model (sdk_version: 08_04, calibrationOption is set to be 64), is it because of the order changing?
Thanks in advance!
