Part Number: AM6412
Hi,
My customer reported boot issues on their custom boards.
5 boards (in 30 boards total) show same behavior.
TI Linux SDK 8.6 is used.
Issue descriptions:
- boot stops at U-boot. There are two failing pattern. Please see two logs (NG1.txt, NG2.txt).
- The boot mode is SD card boot, but the same issue is observed with SPI Flash boot.
- Failing boards do not fail always. Sometimes these boards passed and boot up correctly. After Linux boot, it works fine afterward.
- It seems there is temperature dependency.
Room Temp: 5 boards in 30 boards failed.
60C : 7 boards in 30 boards failed.
-10C : 2 boards in 30 boards failed.
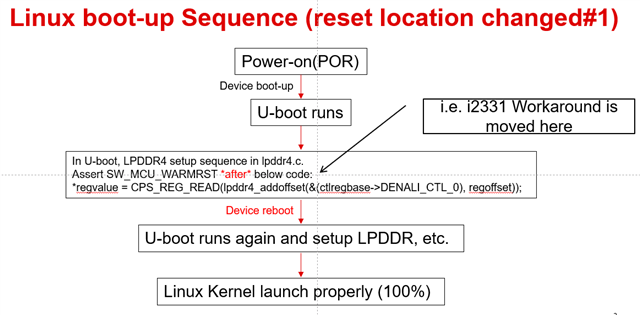
U-Boot SPL 2021.01 (Jul 31 2023 - 11:31:58 +0900) Resetting on cold boot to workaround ErrataID:i2331 resetting ... U-Boot SPL 2021.01 (Jul 31 2023 - 11:31:58 +0900) SYSFW ABI: 3.1 (firmware rev 0x0008 '8.4.7--v08.04.07 (Jolly Jellyfi') SPL initial stack usage: 13424 bytes
U-Boot SPL 2021.01 (Jul 31 2023 - 11:31:58 +0900) Resetting on cold boot to workaround ErrataID:i2331 resetting ... U-Boot SPL 2021.01 (Jul 31 2023 - 11:31:58 +0900) SYSFW ABI: 3.1 (firmware rev 0x0008 '8.4.7--v08.04.07 (Jolly Jellyfi') SPL initial stack usage: 13424 bytes Trying to boot from MMC2 mmc fail to send stop cmd spl_load_image_fat: error reading image tispl.bin, err - -2 SPL: failed to boot from all boot devices ### ERROR ### Please RESET the board ###
What is potential cause of such behavior?
Do you see any idea from these failing logs?
Thanks and regards,
Koichiro Tashiro