Other Parts Discussed in Thread: AM62P
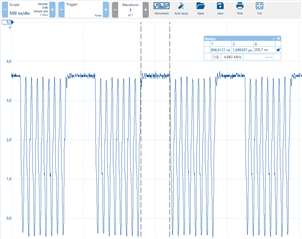
I'm currently working with the MCSPI peripheral on the AM62 SK board using Linux SDK. I have to transfer image-like data and need appropriate bandwidth but when probing the SPI bus I'm seeing that we loose a lot of bandwidth due to regular delays occurring after each sent word (see plot below).
I already reached out to this forum on this topic in an earlier post here. Please read through this post first, the thread is already locked so I need to start a new thread. At this post we enabled DMA which decreased the word delays and with this action we closed the ticket. But now we are using a new peripheral which allows higher transfer rates and now again I struggle satisfying the requirements. Even with DMA the bandwidth is not sufficient and we are forced by the new peripheral to use 25MHz bus clock (not possible to use 50MHz).
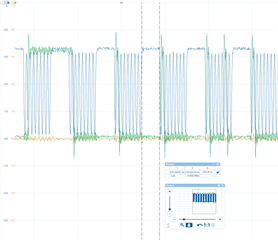
The plot shows the SPI CLK line and we can see that we have a delay of about 200ns after each word sent. It takes about 520ns to transfer one word in total which gets us a bandwidth utilization of around 60%.
Now I wonder if it is possible to decrease those SPI word delays even more?
I also don't know where these delays are introduced (Hardware, Linux kernel, ..), if someone could tell me more about it this would be nice as well.
Thanks in advance,
Claudio