
- Ask a related questionWhat is a related question?A related question is a question created from another question. When the related question is created, it will be automatically linked to the original question.
Hello:
After testing the data interaction between Linux system and R core, it takes a long time to complete a complete read and write cycle using the RPMSG API provided by TI. The data interaction takes too long, so the API provided by TI official can not meet our needs.
Can an A53 core running Linux and a bare metal R5F CPU send interrupts to each other? Trigger the peer party to directly read and write data to the physical address of the agreed shared memory area? Specifically include the following:
1). How does A53 CPU Linux send a signal to R5F CPU like IPC notify between R5F CPU and R5F CPU?Can the Mail Box driver of Linux OS in A53 CPU and IPC Notify of R5F CPU be invoked separately and send interrupt signals to each other?
How to achieve this? Are there any relevant examples?
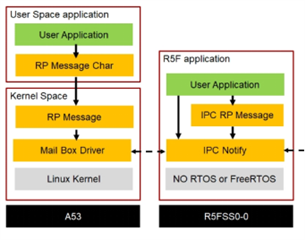
2) Linux systems running on the A53 CPU and bare-metal R5F CPU do not use RP Message for data sending and receiving.
The shared MSRAM memory area between the Linux system and the R5F CPU is directly used for data transfer, and the data is directly copied to the MSRAM shared memory area through the memcpy function for linux system and R5F CPU to read and write access.
Is this method feasible? How to achieve this? Are there any relevant examples?



