Other Parts Discussed in Thread: AM68A,
Tool/software:
Hi,
I am using edge-ai-benchmark tool to benchmark the accuracy metric for Yolov5 model
Tool - https://github.com/TexasInstruments/edgeai-tensorlab
Yolov5 - https://github.com/TexasInstruments/edgeai-yolov5/tree/main
I see there is not edgeai-yolov5 inside model zoo of edgeai-tensorlab. So I move the above yolov5 and it's compiled artifact to edgeai-modelzoo and tried to benchmark the accuracy.
I am getting AP = 0 for all the ranges.
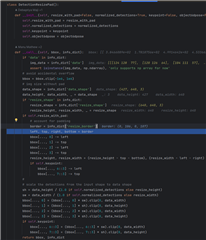
Here is my configuration -
'yolov5_s':utils.dict_update(common_cfg,
preprocess=preproc_transforms.get_transform_onnx(640, 640, reverse_channels=True, resize_with_pad=[True, "corner"], backend='cv2', pad_color=[114, 114, 114]),
session=onnx_session_type(**sessions.get_common_session_cfg(settings, work_dir=work_dir),
runtime_options=settings.runtime_options_onnx_np2(
det_options=True, ext_options={'object_detection:meta_arch_type': 6,
'object_detection:meta_layers_names_list': f'{settings.models_path}/vision/detection/coco/yolov5/yolov5s6_640_ti_lite_metaarch.prototxt',
#'advanced_options:output_feature_16bit_names_list': '1033, 711, 712, 713, 727, 728, 728, 743, 744, 745'
},
fast_calibration=True),
model_path=f'{settings.models_path}/vision/detection/coco/yolov5/yolov5s6_640_ti_lite_37p4_56p0.onnx'),
postprocess=postproc_transforms.get_transform_detection_yolov5_onnx(squeeze_axis=None, normalized_detections=False, resize_with_pad=True, formatter=postprocess.DetectionBoxSL2BoxLS()),
metric=dict(label_offset_pred=datasets.coco_det_label_offset_80to90(label_offset=1)),
model_info=dict(metric_reference={'accuracy_ap[.5:.95]%': 38.3}, model_shortlist=70)
),
And this is what I am getting -
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.000 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.000 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.000 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.000 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.000 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.000 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.000 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.000 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.000 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.000 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.000 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.000
I tried similar things with edgeai-yolox models as well and I can see the accuracy for those models. Not sure what's wrong with yolov5.
Also, just to be on clear side, if yolov5 is giving output in xyxy format, how this edgeai-benchmark tool is converting it to xywh format (if using pycocotools)?
Thanks
Akhilesh