- Ask a related questionWhat is a related question?A related question is a question created from another question. When the related question is created, it will be automatically linked to the original question.
Tool/software:
Team,
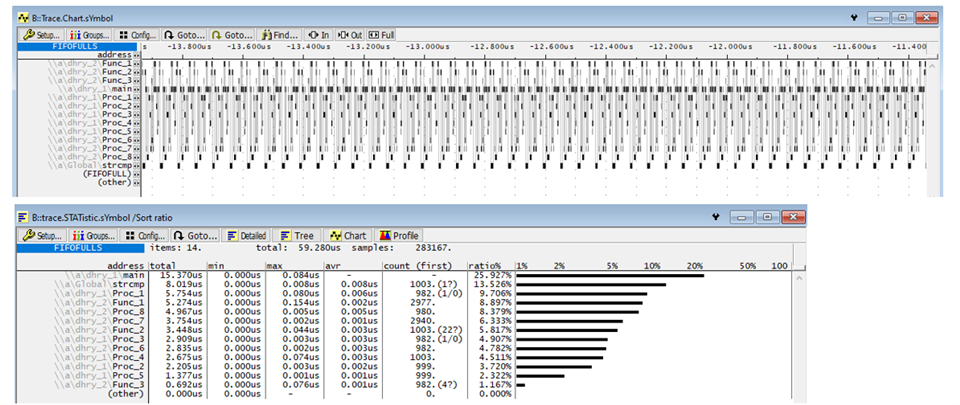
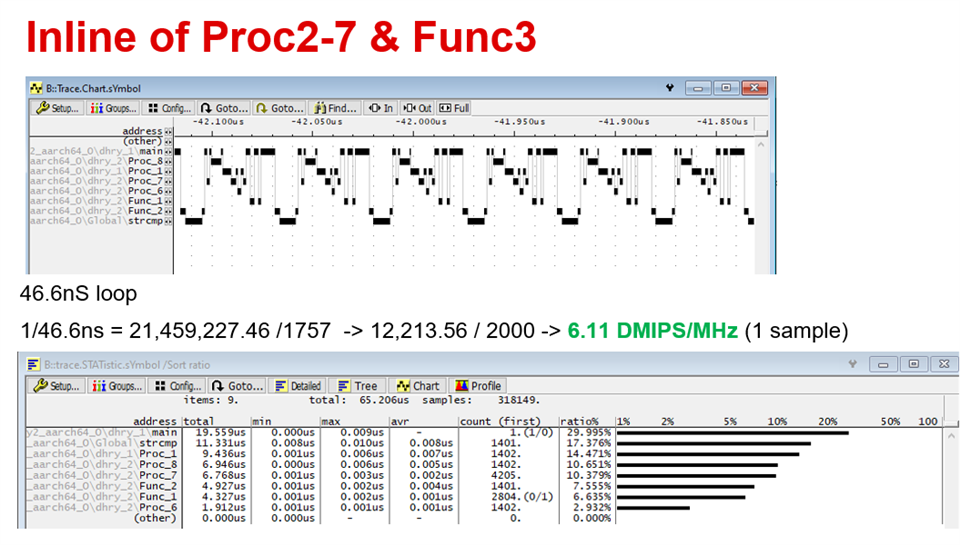
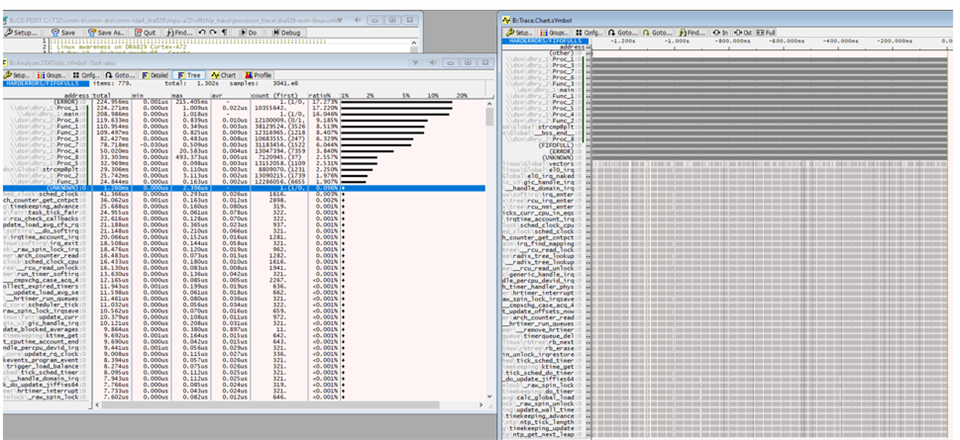
I have been looking at our App note "Sitara AM64x /AM243x Benchmarks https://www.ti.com/lit/pdf/spracv1 " that gives for Dhrystone 3 DMIPS/MHz for each core.
The app note tells that for standard ARM core the DMIPS/MHZ will be identical with the same compiler flags.
Now looking at the AM67x Linux SDK 9.02 benchmarks for Dhrystone:
https://software-dl.ti.com/jacinto7/esd/processor-sdk-linux-am67a/09_02_00/exports/docs/devices/J7_Family/linux/Release_Specific_Performance_Guide.html?highlight=ddr 
It is strange that the DMIPS/Mhz are comparable for the 3 values marked in color as this are different cores (A53, A72), different number of cores (8, 4 and 2) running at different clk speed.
(even if according to the AppNote the Dhrystone benchmarks are run from L1 memory).
Could you please confirm the value that are published?
Can you clarify why the benchmarks are similar?
Thanks in advance,
Anber