Part Number: IND-COMMS-SDK
Tool/software:
Dear TI team,
we've encountered a rather serious issue with the way the AM64x EtherCAT sub-device handles triple-buffering for input (sub-device -> main-device) data.
We first encountered the issue in a custom application, but have been able to recreate the issue with the "Beckhoff" sub-device example just as well.
- Industrial communications SDK 09.02.00.08
- ethercat_slave_beckhoff_ssc_demo on an AM64x EVM (Rev. C, SR2.0 hardware)
- 10 ms EtherCAT main-device cycle
- EtherCAT sub-device configured in free-running mode via 0x1c32.1/0x1c33.1
When configured for free-running mode, PDO_InputMapping is called from MainLoop and during my tests updated the inputs every ~10-16us.
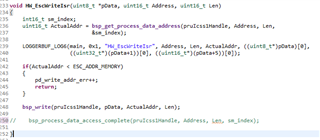
PDO_InputMapping calls HW_EscWriteIsr to write the cyclic inputs to ESC memory. In HW_EscWriteIsr bsp_get_process_data_address is called to get the actual offset of the "current" triple-buffer.
I would have expected the updates to iterate between 2 (or 3?) of the three buffers, but using my logging (very low overhead logging to a ring-buffer in DDR memory) I can see that there are ~600 consecutive writes to one address (0x140e in that case), then ~600 writes to the next address (0x1400), then ~600 writes to the next address (0x1407), then ~600 writes to the next address (again 0x140e), and so on. The time between buffer switching is pretty much exactly 10ms, i.e. every time an EtherCAT frame reads out the SyncManager the PDI gets a different buffer next time it calls bsp_get_process_data_address .
Attached is a CSV file with our logging. The sub-device example is only modified to include our logging facility and log output in HW_EscWriteIsr:
void HW_EscWriteIsr(uint8_t *pData, uint16_t Address, uint16_t Len)
{
int16_t sm_index;
uint16_t ActualAddr = bsp_get_process_data_address(pruIcss1Handle, Address, Len,
&sm_index);
LOGGERBUF_LOG3(main, 0x1, "HW_EscWriteIsr", Address, Len, ActualAddr);
In the logging "ts" and "tsdiff" are measured via R5f cycle counter (800 MHz). The arguments from above loggin ("Address", "Len" and "ActualAddr") are printed in hex and decimal. You can see that from the start PDO_InputMapping kept writing to the buffer at 0x140e until ~600 updates later when it switches to 0x1400. The duration for those ~600 updates is again ~10ms.
This tripe-buffering behavior is problematic because the sub device can't deliver the most recent data to the network if it is continously updating the same buffer. That is also how we noticed the issue in the first place:
- Free running sub-device updating the cyclic input data at ~13x the EtherCAT cycle
- Each update stored an incrementing counter in the input data
- Every EtherCAT cycle would normally show the counter incrementing by 13 or 14 (the cycles are asynchronous), but every once in a while (e.g. ~80 out of 3000000) the counter would NOT increment between two EtherCAT cycles, i.e. we received the same cyclic input data twice.
- That means we didn't get a "slightly" older (where the counter would be +11 or +12 instead of +13/+14 input data update, but we got input data that was a whole EtherCAT cycle old (13 or 14 cyclic input data updates before)
I diffed the EtherCAT sub device firmware between 09.02.00.08 and 09.02.00.15 and these are identical, so I don't expect any fix for this issue in the .15 ind. comms SDK.
We don't know if this problem was also present in older versions, we only noticed it just now.
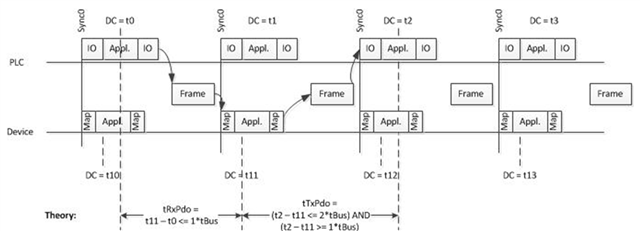
During "normal" SM-synchronous operation you wouldn't directly notice this issue, because in that case there would be one frame for each input data update.
Best Regards,
Dominic