Part Number: AM6421
Tool/software:
Hello.
Need some help with adjusted example code with slightly different functionality.
I'm trying to configure DMA to transfer packets from a queue in TCM to DDR or MSRAM by using DMA.
Started from the swtrigger example, with the difference that total space available is different for source/destination queues.
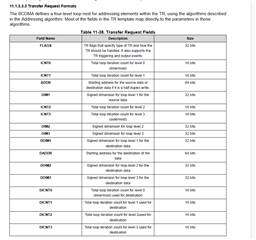
To get into context and make things easier here are some definitions (test values):
- entrySize = 32 Bytes
- chunkSize = 28160 Bytes
- srcSize = 56320 Bytes
- destSize = 506880
The idea is to transfer a chunk with every sw_trigger event at a time... (hence src/dest sizes are multiple of chunkSize which also multiple of entrySize). The total chunks are not fixed/known and data is to be filled in src queue by an external driven event (GPIO interrupt).
The A53 is running Linux, and this code is running in R5FSS0_0 (single core mode).
Here is the code that is not working:
// TCM (by linker)
volatile BOOL bDMADone = TRUE;
uint32_t triggerMask = 0;
volatile uint32_t* ch0SwTriggerReg = NULL;
Udma_EventObject gCh0TrEventObj __attribute__((section("MSRAM"))) = { 0 };
Udma_EventHandle gCh0TrEventHandle __attribute__((section("MSRAM"))) = NULL;
volatile Udma_EventPrms gCh0TrEventPrms __attribute__((section("MSRAM"))) = { 0 };
Udma_ChHandle ch0Handle __attribute__((section("MSRAM"))) = NULL;
uint8_t gUdmaTestTrpdMem[UDMA_TRPD_SIZE] __attribute__((aligned(UDMA_CACHELINE_ALIGNMENT), section("MSRAM")));
// Debug counters
volatile uint32_t uiEnqueues = 0;
volatile uint32_t uiEnqueueCBs = 0;
void App_udmaEventCb(Udma_EventHandle eventHandle, uint32_t eventType, void* appData)
{
uiEnqueueCBs++;
bDMADone = TRUE;
}
static void App_udmaTrpdInit(Udma_ChHandle chHandle, uint32_t chIdx, uint8_t* trpdMem, const void* destBuf, const void* srcBuf, uint32_t destSize, uint32_t srcSize, uint32_t chunkSize, uint32_t entrySize)
{
CSL_UdmapTR15* pTr;
uint32_t cqRingNum = Udma_chGetCqRingNum(chHandle);
/* Make TRPD with TR15 TR type */
UdmaUtils_makeTrpdTr15(trpdMem, 1U, cqRingNum);
/* Setup TR */
pTr = UdmaUtils_getTrpdTr15Pointer(trpdMem, 0U);
pTr->flags = CSL_FMK(UDMAP_TR_FLAGS_TYPE, CSL_UDMAP_TR_FLAGS_TYPE_4D_BLOCK_MOVE_REPACKING_INDIRECTION);
//pTr->flags |= CSL_FMK(UDMAP_TR_FLAGS_WAIT, 1U);
pTr->flags |= CSL_FMK(UDMAP_TR_FLAGS_STATIC, 0U);
pTr->flags |= CSL_FMK(UDMAP_TR_FLAGS_EOL, CSL_UDMAP_TR_FLAGS_EOL_ICNT0_ICNT1);
pTr->flags |= CSL_FMK(UDMAP_TR_FLAGS_EVENT_SIZE, CSL_UDMAP_TR_FLAGS_EVENT_SIZE_ICNT2_DEC);
pTr->flags |= CSL_FMK(UDMAP_TR_FLAGS_TRIGGER0, CSL_UDMAP_TR_FLAGS_TRIGGER_GLOBAL0);
pTr->flags |= CSL_FMK(UDMAP_TR_FLAGS_TRIGGER0_TYPE, CSL_UDMAP_TR_FLAGS_TRIGGER_TYPE_ICNT2_DEC);
pTr->flags |= CSL_FMK(UDMAP_TR_FLAGS_TRIGGER1, CSL_UDMAP_TR_FLAGS_TRIGGER_NONE);
pTr->flags |= CSL_FMK(UDMAP_TR_FLAGS_TRIGGER1_TYPE, CSL_UDMAP_TR_FLAGS_TRIGGER_TYPE_ALL);
pTr->flags |= CSL_FMK(UDMAP_TR_FLAGS_CMD_ID, 0x25U); /* This will come back in TR response */
pTr->flags |= CSL_FMK(UDMAP_TR_FLAGS_SA_INDIRECT, 0U);
pTr->flags |= CSL_FMK(UDMAP_TR_FLAGS_DA_INDIRECT, 0U);
pTr->flags |= CSL_FMK(UDMAP_TR_FLAGS_EOP, 1U);
pTr->addr = (uint64_t)Udma_defaultVirtToPhyFxn(srcBuf, 0U, NULL);
pTr->icnt0 = entrySize; // 32B
pTr->icnt1 = chunkSize / entrySize; // 28160 / 32 = 880
pTr->icnt2 = srcSize / chunkSize; // 56320 / 28160 = 2
pTr->icnt3 = (uint16_t)-1; // ???? should be infinite ????
pTr->dim1 = entrySize; // 32
pTr->dim2 = chunkSize; // 28160
pTr->dim3 = 0;
pTr->daddr = (uint64_t)Udma_defaultVirtToPhyFxn(destBuf, 0U, NULL);
pTr->dicnt0 = entrySize; // 32B
pTr->dicnt1 = chunkSize / entrySize; // 28160 / 32 = 880
pTr->dicnt2 = destSize / chunkSize; // 506880 / 28160 = 18
pTr->dicnt3 = (uint16_t)-1; // ???? should be infinite ????
pTr->ddim1 = entrySize; // 32
pTr->ddim2 = chunkSize; // 28160
pTr->ddim3 = 0;
pTr->fmtflags = 0x00000000U; /* Linear addressing, 1 byte per elem */
/* Perform cache writeback */
CacheP_wb(trpdMem, UDMA_TRPD_SIZE, CacheP_TYPE_ALLD);
return;
}
static void App_udmaTriggerInit(void)
{
int32_t retVal;
Udma_DrvHandle drvHandle = &gUdmaDrvObj[CONFIG_UDMA0];
gCh0TrEventHandle = &gCh0TrEventObj;
UdmaEventPrms_init((Udma_EventPrms*)& gCh0TrEventPrms);
gCh0TrEventPrms.eventType = UDMA_EVENT_TYPE_TR;
gCh0TrEventPrms.eventMode = UDMA_EVENT_MODE_SHARED;
gCh0TrEventPrms.chHandle = ch0Handle;
gCh0TrEventPrms.controllerEventHandle = NULL;
gCh0TrEventPrms.eventCb = App_udmaEventCb;
gCh0TrEventPrms.appData = NULL;
retVal = Udma_eventRegister(drvHandle, gCh0TrEventHandle, (Udma_EventPrms*)&gCh0TrEventPrms);
if (UDMA_SOK != retVal)
DebugMsg("\nWarning! - Udma_eventRegister ch0 = %d", retVal);
retVal = Udma_chEnable(ch0Handle);
if (UDMA_SOK != retVal)
DebugMsg("\nWarning! - Udma_chEnable ch0 = %d", retVal);
return;
}
STATUS dma_init(VOID* destBuf, VOID* srcBuf, uint32_t destSize, uint32_t srcSize, uint32_t chunkSize, uint32_t entrySize)
{
int32_t retVal = UDMA_SOK;
uint8_t* trpdMem;
uint64_t trpdMemPhy;
srcBuf = (VOID*)TCM_ADDR_TO_PHY((uint32_t)srcBuf);
ch0Handle = gConfigUdma0BlkCopyChHandle[0]; /* Has to be done after driver open */
App_udmaTrpdInit(ch0Handle, 0, &gUdmaTestTrpdMem[0], destBuf, srcBuf, destSize, srcSize, chunkSize, entrySize);
App_udmaTriggerInit();
triggerMask = ((uint32_t)1U << (CSL_UDMAP_TR_FLAGS_TRIGGER_GLOBAL0 - 1U));
ch0SwTriggerReg = (volatile uint32_t*)Udma_chGetSwTriggerRegister(ch0Handle);
trpdMem = &gUdmaTestTrpdMem[0];
trpdMemPhy = (uint64_t)Udma_defaultVirtToPhyFxn(trpdMem, 0U, NULL);
retVal = Udma_ringQueueRaw(Udma_chGetFqRingHandle(ch0Handle), trpdMemPhy);
if (UDMA_SOK != retVal)
DebugMsg("\nWarning! - Udma_ringQueueRaw ch0 = %d", retVal);
return ERROR_SUCCESS;
}
VOID dma_enqueue(VOID)
{
// Trigger DMA
bDMADone = FALSE;
CSL_REG32_WR(ch0SwTriggerReg, triggerMask);
CSL_REG32_WR(ch0SwTriggerReg, 0U);
uiEnqueues++;
}
BOOL dma_done(VOID)
{
return bDMADone;
}
STATUS dma_end(VOID)
{
int32_t retVal;
uint64_t pDesc;
retVal = Udma_chDisable(ch0Handle, UDMA_DEFAULT_CH_DISABLE_TIMEOUT);
if (UDMA_SOK != retVal)
DebugMsg("\nWarning! - Udma_chDisable ch0 = %d", retVal);
retVal = Udma_ringFlushRaw(Udma_chGetCqRingHandle(ch0Handle), &pDesc);
if (UDMA_SOK != retVal)
DebugMsg("\nWarning! - Udma_ringDequeueRaw ch0 = %d", retVal);
retVal = Udma_eventUnRegister(gCh0TrEventHandle);
if (UDMA_SOK != retVal)
DebugMsg("\nWarning! - Udma_eventUnRegister ch0 = %d", retVal);
return ERROR_SUCCESS;
}
The calling order will be:
dma_init(xxxxx);
while (not_done) {
dma_enqueue();
if (dma_done())
xxxxxxx; // dequeue src AND enqueue dest
}
dma_end();
Any help will be appreciated.
Thanks.