Tool/software:
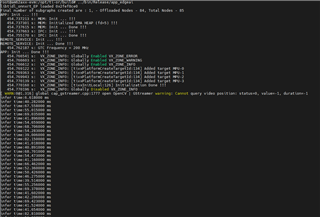
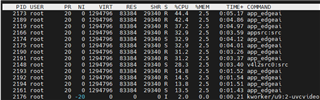
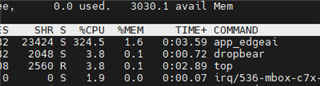
could run cpu+npu in the same time based on edgeai-gst-apps /app_cpp. We tried to delete allownodes.txt 's contents And tried add these code to postprocess part .
auto allocator_info = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);Ort::Value input_tensor_ = Ort::Value::CreateTensor<float>(allocator_info, input_image_.data(), input_image_.size(), input_shape.data(), input_shape.size());auto cpu_output = ort_session->Run(Ort::RunOptions{ nullptr }, &input_names[0], &input_tensor_, 1, output_names.data(), 1);const float* output_cpu = cpu_output[0].GetTensorMutableData<float>();But all the fps will down to 5 . Is that normal?



 。但是超过128次或是用while1到128次就直接结束了
。但是超过128次或是用while1到128次就直接结束了
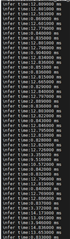
 如果我在warmup后面实现类似摄像头循环读图片再处理的效果,infertime不一致
如果我在warmup后面实现类似摄像头循环读图片再处理的效果,infertime不一致