A related question is a question created from another question. When the related question is created, it will be automatically linked to the original question.
If you have a related question, please click the "Ask a related question" button in the top right corner. The newly created question will be automatically linked to this question.
PROCESSOR-SDK-AM69A: Issue Deploying Custom iResNet101_Ada Model on AM69A with TIDL
I am currently working on deploying a custom iresnet101_ada model using TensorFlow Lite on the AM69A platform with TIDL. I successfully ran the provided inference example with a pre-compiled model, but when using my own model, I encountered issues.
Issue Summary: The compiled artifacts from my custom iresnet101_ada model contain two subgraphs and do not generate the allowedNode.txt file.
When running inference using test_tflite.py, I receive the following error messages:
VX_ZONE_ERROR: [ownNodeKernelInit:604] Target kernel, TIVX_CMD_NODE_CREATE failed for node TIDLNode VX_ZONE_ERROR: [ownNodeKernelInit:606] If the target callbacks have been registered, please ensure no errors are occurring within the create callback of this kernel VX_ZONE_ERROR: [ownGraphNodeKernelInit:690] kernel init for node 0, kernel com.ti.tidl:1:1 ... failed !!! VX_ZONE_ERROR: [ TIDL subgraph Identity ] Graph verify failed TIDL_RT_OVX: ERROR: Verify OpenVX graph failed
The system logs indicate that 354 nodes were delegated out of 354, suggesting that the model was fully offloaded to TIDL.
Questions: Subgraph Issue: Why does my model generate two subgraphs instead of one? Is there a way to force a single subgraph in TIDL compilation? Missing allowedNode.txt: The compilation process does not generate allowedNode.txt. Could this indicate an issue with model partitioning or unsupported layers? Graph Initialization Failure: The log mentions TIVX_CMD_NODE_CREATE failed for node TIDLNode. How can I debug this further? Are there specific TIDL settings required for models like iresnet101_ada? Recommended Debugging Steps: What steps should I follow to properly validate and debug the TIDL compilation and inference pipeline for this model? Additional Information: I used the standard TIDL compilation flow for TensorFlow Lite. The original model is a modified iResNet101 architecture trained for 112x112 input images. I appreciate any guidance you can provide on resolving these issues.
Subgraph Issue: Every time a node is processed on the ARM core, a new subnode is created. Please check any unsupported layers.
Graph Initialization Failure: This could be a number of things. Please try s simple standard ONNX model (like resnet18 or any model you know runs) and see if it runs. I have seen this when the SD card gets corrupted. This is to test if your env is good.
Try: in examples/osrt_python/ort first. You will need to add your model in model_config.py in osrt_python/ first. Then run python3 ./onxxrt_ep.py -d -m model
If you get an input tensor error. Then try the same thing in examples/osrt_python/advanced_examples/unit_tests_validation/ort, this will generate a random input tensor of the right size.
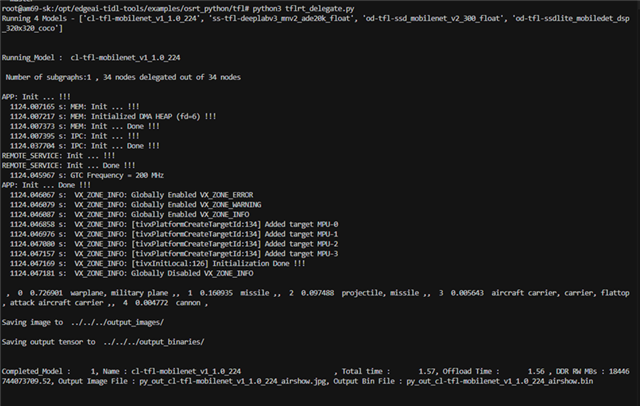
I have tested running models using the command python3 tflrt_delegate.py, as shown in the image below, and it executed successfully.
Upon checking, I found that when compiling, the layer model_102/tf.compat.v1.transpose_49/transpose is not supported. Therefore, I added it to deny_list:layer_type to prevent this layer from running on C7x-MMA. However, the error still persists.
Could you take a look at the graphvizInfo.txt file below?
The screenshot you are displaying is the run of the out-of-the-box models, not your model. Can you please send me your model, configuration files, and the command line for how you run it? I will check it out.
Sorry forgot to include this earlier but I also need details on the configuration files and the command line on how you ran it still, just like Chris mentioned.
Also, TI has holiday tomorrow (Friday). Please know any responses will be delayed until Monday morning CST.
I’ve used the latest version 10_01_04_00, and the models have been compiled with the appropriate c7x_firmware_version compilation option as indicated in the compatibility table notes.
Thank you for the information. In this case, I still need the configuration files and the command line on how you ran if possible so I can further investigate.
Could you help to elaborate on needed configuration files and the command line? Where could customer get the info to send to you? Sorry1 We are not sure about this.
Just the compilation logs for the command line works. For the configuration files, in model_configs under the osrt_python directory, there is the configuration that we are asking for.
Also, could they try this under advanced_examples? This is found through the same path, but from osrt_python, go to advanced_examples --> unit_tests_validation. Same situation, but I have seen this runs better. Could they also try in a docker environment so there is no dependencies?
Thank you for sharing. I will investigate further and see if I can recreate your issue. I will keep you updated on any updates or questions I may have.
I was able to run your model without any hangs or errors under advanced_examples. I have attached the artifacts I generated, which includes 1 subgraph, as well as the output I received when running inference.
For documentation on how to run custom model, please reference this link which will explain in detail:github.com/.../README.md
I am going to list out the steps I took as well since the method you are using is missing some steps to run your model correctly. When running on OSRT, there are two flows you can use depending on the type of model you are using (TfLite vs ONNX). In this case you are using ONNX, so the flow you would use would also fall under ONNX (also labelled ORT under TIDL for Onnx RunTime)
First step is to keep make sure the OSRT can find and generate artifacts properly for your model.
The location and commands I used for this is as follow. I did this under a docker in edgeai-tidl-tools. You can also run this under just "examples" and not use advanced_examples, but I find advanced_examples to be easier to use.
- cd home/root/examples/osrt_python/advanced_examples/unit_tests_validation
- vi common_utils.py
- around line 94, you will see models_configs with some example models under ##onnx. I added a configuration for your model here and changed the model_path to reflect where I kept your model.
'arrow' : { 'model_path' : os.path.join('../../../../../models/Arrow', 'resnet101.onnx'), 'source' : {'model_url': 'dummy', 'opt': True}, # URL irrelavant if model present in specified path 'num_images' : numImages, 'task_type': 'classification' },
- follow the instructions in the README and create the required directories for onnx models.
mkdir outputs/output_ref/onnx for onnx models mkdir outputs/output_test/onnx for onnx models
- cd ort/
- vi onnxrt_ep.py
-around line 255, you will see "models = ['default model name']. Change the name so it is the name of your model. In my case, it was
models = ['arrow']
- To compile your artifacts, run python3 ./onnxrt_ep.py -c
- To run inference, run python3 ./onnxrt_ep.py
- The model-artifacts can be found in the previous unit_tests_validation directory, which should generate the artifacts you compiled.
- For the outputs, outputs/output_test/onnx directory you created from the README instructions will have your output bin.
Please let me know if you have any questions or if you are confused on any of the instructions I shared. If I missed the main issue, please let me know.
Hi Christina Kuruvilla i have embedded engineer in CMC company , i have been complete resnet101.onnx on dev kit AM69A , total time: 526.52 1. What unit is total time in? 2. How to check time inference test resnet 101 on AM69A?
1. The total time should be in milliseconds [ms]. Correction: Actual time is in microseconds.
2. For check the inference time on the board, you can use TIDL tools to give you total inference time when running (prints it after completed), as well as layer details as well.
If you have any other questions that are new, please start a new E2e thread. We like to keep new issues on a new E2e so it can be referenced by others easier.
Please create a new E2e post for this, as it is a separate issue than what is for this thread, which was related to compiling resulting in a missing allowedNode.txt.
We limit each E2e to one topic, so this new question regarding inference time warrants a new E2e. This is for our own organization and so others with similar questions can reference the answer quickly.
If I have answered the original question, and it is resolved, we can close this thread and move to the new one.