Part Number: DRA821U
Tool/software:
Hi team,
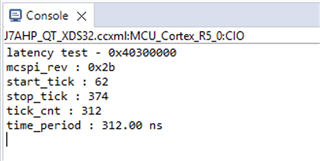
Customer is seeing that writing device registers such as GPIO output value change or configuring MCSPI takes quite a long time, almost 1us. This seems pretty low performance for such a powerful chip.
Couple questions on this:
- What might they be doing wrong that is causing this behavior?
- Is it a correct solution to increase the CBASS clock?
- They tried to do this in u-boot using the procedure described in paragraph 5.4.5.7.4 (DRA821U TRM rev. D), but writing to PLLDIV1 and PLLDIV2 registers has no effect. They remain with values 24 (0x8017) and 1 (0x8000).
- They are able to change the value of a PLL0_FREQ_CTRL0 register, but it influences too many other things.
Any advice on how to improve performance is appreciated!
Best,
Luke