Part Number: AM623
Other Parts Discussed in Thread: SK-AM62B-P1
Tool/software:
In SDK11.0.9 release notes as below, it is reported from SDK10, is it new issue starts from SDK10 or is it exist for long?
|
EXT_EP-12076 |
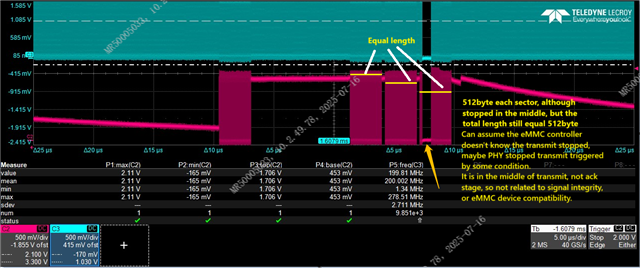
copying files to eMMC triggers cqe error |
Is it software driver issue or hardware related? Is there more analysis result of it?