Tool/software:
I am currently on the SDK 10.1 for SK-AM62A-LP. I am trying to train and compile a yolox-nano-lite model using the branch r10.1 from edgeai-tensorlab. My dataset follows the standard COCO format. I have tried two ways of doing the same -
1. Using edgeai-mmdetection for model training and using edgeai-benchmark for compiling the model. I convert the trained pytorch weights to ONNX and then compile it generate artifacts for inference.
2. Using edgeai-modelmaker's config-detection.yaml with the run_modelmaker.py script, on my dataset in the COCO format.
For the first approach with edgeai-mmdetection I am able to get the trained model and the corresponding ONNX and proto files, using tools/train.py. I have referred the tutorials mentioned in the edgeai-benchmark for compiling the model, but getting mAP = 0 after compilation of the model. I have kept the tensor_bits = 32 so that no calibration is needed and we can directly just compile the model.
[34m
INFO:[33m20250726-065738: starting - [39mod-mlpefmnv1_onnxrt_2025_07_09_11_31_38_yolox_nano_lite_dump_ep300_lr0.002_b64_onnx_exports_yolox_nano_lite_dump_onnx
[34m
INFO:[33m20250726-065738: running - [39mod-mlpefmnv1_onnxrt_2025_07_09_11_31_38_yolox_nano_lite_dump_ep300_lr0.002_b64_onnx_exports_yolox_nano_lite_dump_onnx
[34m
INFO:[33m20250726-065738: pipeline_config - [39m{'task_type': 'detection', 'dataset_category': 'coco', 'calibration_dataset': <edgeai_benchmark.datasets.coco_det.COCODetection object at 0x7fb038d2c3d0>, 'input_dataset': <edgeai_benchmark.datasets.coco_det.COCODetection object at 0x7fb038d2c400>, 'preprocess': <edgeai_benchmark.preprocess.PreProcessTransforms object at 0x7fafff3d6680>, 'session': <edgeai_benchmark.sessions.onnxrt_session.ONNXRTSession object at 0x7fafff3d6380>, 'postprocess': <edgeai_benchmark.postprocess.PostProcessTransforms object at 0x7fafff3d65f0>, 'metric': {'label_offset_pred': {0: 1, -1: 0, 1: 2}}}
[34m
INFO:[33m20250726-065738: import - [39mod-mlpefmnv1_onnxrt_2025_07_09_11_31_38_yolox_nano_lite_dump_ep300_lr0.002_b64_onnx_exports_yolox_nano_lite_dump_onnx - this may take some time...
[34mINFO:[33m20250726-065738: model_path - [39m/opt/code/edgeai-mmdetection/work_dirs/2025_07_09_11_31_38_yolox_nano_lite_dump_ep300_lr0.002_b64/onnx_exports/yolox_nano_lite_dump.onnx
[34mINFO:[33m20250726-065738: model_file - [39m/opt/code/edgeai-benchmark/work_dirs_custom/modelartifacts/32bits/od-mlpefmnv1_onnxrt_2025_07_09_11_31_38_yolox_nano_lite_dump_ep300_lr0.002_b64_onnx_exports_yolox_nano_lite_dump_onnx/model/yolox_nano_lite_dump.onnx
[34mINFO:[33m20250726-065738: quant_file - [39m/opt/code/edgeai-benchmark/work_dirs_custom/modelartifacts/32bits/od-mlpefmnv1_onnxrt_2025_07_09_11_31_38_yolox_nano_lite_dump_ep300_lr0.002_b64_onnx_exports_yolox_nano_lite_dump_onnx/model/yolox_nano_lite_dump_qparams.prototxt
Downloading 1/1: /opt/code/edgeai-mmdetection/work_dirs/2025_07_09_11_31_38_yolox_nano_lite_dump_ep300_lr0.002_b64/onnx_exports/yolox_nano_lite_dump.onnx
Download done for /opt/code/edgeai-mmdetection/work_dirs/2025_07_09_11_31_38_yolox_nano_lite_dump_ep300_lr0.002_b64/onnx_exports/yolox_nano_lite_dump.onnx
Downloading 1/1: /opt/code/edgeai-mmdetection/work_dirs/2025_07_09_11_31_38_yolox_nano_lite_dump_ep300_lr0.002_b64/onnx_exports/yolox_nano_lite_dump.onnx
Download done for /opt/code/edgeai-mmdetection/work_dirs/2025_07_09_11_31_38_yolox_nano_lite_dump_ep300_lr0.002_b64/onnx_exports/yolox_nano_lite_dump.onnx
Converted model is valid!
[33m[TIDL Import] WARNING: tensor_bits = 32, Compiling for floating point - target execution is not supported for 32 bit compilation[0m
[35;1m========================= [Model Compilation Started] =========================
[0mModel compilation will perform the following stages:
1. Parsing
2. Graph Optimization
3. Quantization & Calibration
4. Memory Planning
[35;1m============================== [Version Summary] ==============================
[0m-------------------------------------------------------------------------------
| TIDL Tools Version | [32;1m10_01_04_00[0m |
-------------------------------------------------------------------------------
| C7x Firmware Version | [32;1m10_01_00_01[0m |
-------------------------------------------------------------------------------
| Runtime Version | [32;1m1.15.0[0m |
-------------------------------------------------------------------------------
| Model Opset Version | [32;1m17[0m |
-------------------------------------------------------------------------------
[35;1m============================== [Parsing Started] ==============================
[0myolox is meta arch name
yolox
Number of OD backbone nodes = 191
Size of odBackboneNodeIds = 191
------------------------- Subgraph Information Summary -------------------------
-------------------------------------------------------------------------------
| Core | No. of Nodes | Number of Subgraphs |
-------------------------------------------------------------------------------
| C7x | 267 | 3 |
| CPU | 4 | x |
-------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------------------
| Node | Node Name | Reason |
------------------------------------------------------------------------------------------------------------------------
| Transpose | 6 | For firmware version < 10_01_04_00, only permutes are suported when number of dimensions > 4 |
| MaxPool | 79 | Kernel size (13x13) with stride (1x1) not supported |
| MaxPool | 78 | Kernel size (9x9) with stride (1x1) not supported |
| MaxPool | 77 | Kernel size (5x5) with stride (1x1) not supported |
------------------------------------------------------------------------------------------------------------------------
[35;1m============================= [Parsing Completed] =============================
[0m[35;1m==================== [Optimization for subgraph_0 Started] ====================
[0m----------------------------- Optimization Summary -----------------------------
------------------------------------------------------------------------------
| Layer | Nodes before optimization | Nodes after optimization |
------------------------------------------------------------------------------
| TIDL_BatchNormLayer | 0 | 1 |
| TIDL_EltWiseLayer | 2 | [32;1m0[0m |
| TIDL_CastLayer | 1 | [32;1m0[0m |
------------------------------------------------------------------------------
[35;1m=================== [Optimization for subgraph_0 Completed] ===================
[0mThe soft limit is 10240
The hard limit is 10240
MEM: Init ... !!!
MEM: Init ... Done !!!
0.0s: VX_ZONE_INIT:Enabled
0.9s: VX_ZONE_ERROR:Enabled
0.10s: VX_ZONE_WARNING:Enabled
0.8996s: VX_ZONE_INIT:[tivxInit:190[34m
INFO:[33m20250726-065752: import completed - [39mod-mlpefmnv1_onnxrt_2025_07_09_11_31_38_yolox_nano_lite_dump_ep300_lr0.002_b64_onnx_exports_yolox_nano_lite_dump_onnx - 14 sec
[32m
SUCCESS:[33m20250726-065752: benchmark results - [39m{}
] Initialization Done !!!
[35;1m============= [Quantization & Calibration for subgraph_0 Started] =============
[0m[35;1m==================== [Optimization for subgraph_1 Started] ====================
[0m----------------------------- Optimization Summary -----------------------------
--------------------------------------------------------------------------------
| Layer | Nodes before optimization | Nodes after optimization |
--------------------------------------------------------------------------------
| TIDL_EltWiseLayer | 7 | 7 |
| TIDL_ConcatLayer | 3 | 3 |
| TIDL_ReLULayer | 29 | [32;1m0[0m |
| TIDL_ConvolutionLayer | 29 | 29 |
--------------------------------------------------------------------------------
[35;1m=================== [Optimization for subgraph_1 Completed] ===================
[0m[35;1m============= [Quantization & Calibration for subgraph_1 Started] =============
[0mTIDL Meta pipeLine (proto) file : /opt/code/edgeai-benchmark/work_dirs_custom/modelartifacts/32bits/od-mlpefmnv1_onnxrt_2025_07_09_11_31_38_yolox_nano_lite_dump_ep300_lr0.002_b64_onnx_exports_yolox_nano_lite_dump_onnx/model/yolox_nano_lite_dump.prototxt
yolox
yolox
[35;1m==================== [Optimization for subgraph_2 Started] ====================
[0m[33m[TIDL Import] [PARSER] WARNING: Requested output data convert layer is not added to the network, It is currently not optimal[0m
[33m[TIDL Import] [PARSER] WARNING: Requested output data convert layer is not added to the network, It is currently not optimal[0m
----------------------------- Optimization Summary -----------------------------
-------------------------------------------------------------------------------------
| Layer | Nodes before optimization | Nodes after optimization |
-------------------------------------------------------------------------------------
| TIDL_OdOutputReformatLayer | 0 | 2 |
| TIDL_DetectionOutputLayer | 0 | 1 |
| TIDL_ResizeLayer | 2 | 2 |
| TIDL_ConvolutionLayer | 54 | 54 |
| TIDL_ReLULayer | 45 | [32;1m0[0m |
| TIDL_ConcatLayer | 13 | 13 |
-------------------------------------------------------------------------------------
[35;1m=================== [Optimization for subgraph_2 Completed] ===================
[0m[35;1m============= [Quantization & Calibration for subgraph_2 Started] =============
[0mMEM: Deinit ... !!!
MEM: Alloc's: 86 alloc's of 196291083 bytes
MEM: Free's : 86 free's of 196291083 bytes
MEM: Open's : 0 allocs of 0 bytes
MEM: Deinit ... Done !!!
[34m
INFO:[33m20250726-065752: starting - [39mod-mlpefmnv1_onnxrt_2025_07_09_11_31_38_yolox_nano_lite_dump_ep300_lr0.002_b64_onnx_exports_yolox_nano_lite_dump_onnx
[34m
INFO:[33m20250726-065752: running - [39mod-mlpefmnv1_onnxrt_2025_07_09_11_31_38_yolox_nano_lite_dump_ep300_lr0.002_b64_onnx_exports_yolox_nano_lite_dump_onnx
[34m
INFO:[33m20250726-065752: pipeline_config - [39m{'task_type': 'detection', 'dataset_category': 'coco', 'calibration_dataset': <edgeai_benchmark.datasets.coco_det.COCODetection object at 0x7fb038d2c3d0>, 'input_dataset': <edgeai_benchmark.datasets.coco_det.COCODetection object at 0x7fb038d2c400>, 'preprocess': <edgeai_benchmark.preprocess.PreProcessTransforms object at 0x7fafff3d6680>, 'session': <edgeai_benchmark.sessions.onnxrt_session.ONNXRTSession object at 0x7fafff3d6380>, 'postprocess': <edgeai_benchmark.postprocess.PostProcessTransforms object at 0x7fafff3d65f0>, 'metric': {'label_offset_pred': {0: 1, -1: 0, 1: 2}}}
[34m
INFO:[33m20250726-065752: infer - [39mod-mlpefmnv1_onnxrt_2025_07_09_11_31_38_yolox_nano_lite_dump_ep300_lr0.002_b64_onnx_exports_yolox_nano_lite_dump_onnx - this may take some time...
[34mINFO:[33m20250726-065752: model_path - [39m/opt/code/edgeai-mmdetection/work_dirs/2025_07_09_11_31_38_yolox_nano_lite_dump_ep300_lr0.002_b64/onnx_exports/yolox_nano_lite_dump.onnx
[34mINFO:[33m20250726-065752: model_file - [39m/opt/code/edgeai-benchmark/work_dirs_custom/modelartifacts/32bits/od-mlpefmnv1_onnxrt_2025_07_09_11_31_38_yolox_nano_lite_dump_ep300_lr0.002_b64_onnx_exports_yolox_nano_lite_dump_onnx/model/yolox_nano_lite_dump.onnx
[34mINFO:[33m20250726-065752: quant_file - [39m/opt/code/edgeai-benchmark/work_dirs_custom/modelartifacts/32bits/od-mlpefmnv1_onnxrt_2025_07_09_11_31_38_yolox_nano_lite_dump_ep300_lr0.002_b64_onnx_exports_yolox_nano_lite_dump_onnx/model/yolox_nano_lite_dump_qparams.prototxt
infer : od-mlpefmnv1_onnxrt_2025_07_09_11_31_38_yolox_nano_l| 0%| || 0/100 [00:00<?, ?it/s]
infer : od-mlpefmnv1_onnxrt_2025_07_09_11_31_38_yolox_nano_l| | 0% 0/100| [< ]
infer : od-mlpefmnv1_onnxrt_2025_07_09_11_31_38_yolox_nano_l| 51%|█████ || 51/100 [00:10<00:09, 5.06it/s]
infer : od-mlpefmnv1_onnxrt_2025_07_09_11_31_38_yolox_nano_l| 100%|██████████|| 100/100 [00:19<00:00, 5.23it/s]
[34m
INFO:[33m20250726-065812: infer completed - [39mod-mlpefmnv1_onnxrt_2025_07_09_11_31_38_yolox_nano_lite_dump_ep300_lr0.002_b64_onnx_exports_yolox_nano_lite_dump_onnx - 19 sec
[32m
SUCCESS:[33m20250726-065812: benchmark results - [39m{'infer_path': 'od-mlpefmnv1_onnxrt_2025_07_09_11_31_38_yolox_nano_lite_dump_ep300_lr0.002_b64_onnx_exports_yolox_nano_lite_dump_onnx', 'accuracy_ap[.5:.95]%': 0.0, 'accuracy_ap50%': 0.0, 'num_subgraphs': 3}
libtidl_onnxrt_EP loaded 0x56250a2aa320
Final number of subgraphs created are : 3, - Offloaded Nodes - 267, Total Nodes - 271
The soft limit is 10240
The hard limit is 10240
MEM: Init ... !!!
MEM: Init ... Done !!!
0.0s: VX_ZONE_INIT:Enabled
0.11s: VX_ZONE_ERROR:Enabled
0.12s: VX_ZONE_WARNING:Enabled
0.4419s: VX_ZONE_INIT:[tivxInit:190] Initialization Done !!!
MEM: Deinit ... !!!
MEM: Alloc's: 86 alloc's of 196291083 bytes
MEM: Free's : 86 free's of 196291083 bytes
MEM: Open's : 0 allocs of 0 bytes
MEM: Deinit ... Done !!!
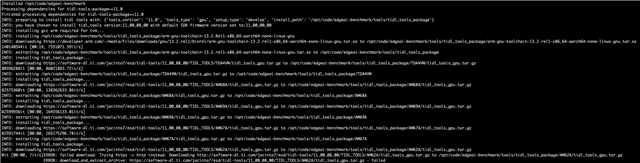
For the second approach I have used edgeai-modelmaker and modified the default config_detection.yaml to use my COCO format dataset. The compilation in this case gets completed with errors such as "Invalid Layer Name /multi_level_conv_cls.0/Conv_output_0". Attaching the compilation log for the same -
modelmaler_compilation_run.log
I have validated that I am able to get predictions from the model in the ONNX format and it's mAP is not zero. However I am facing the above issues while trying to compile the models for inference on the SK-AM62A-LP SOC. I have uploaded the logs I felt necessary for conveying this issue. Do let me know should you require any additional files for debugging. Please suggest the potential issues and solutions.
Thank you