



Tool/software:
Hi,
My original issue is documented here.
I recently ran YOLOPv2 with Debug Traces at level 3 according to this documentation.
I will go step by step through the section.
1.
It is recommended to first test the inference of a given network in host/pc (x86_pc) emulation mode to make sure output is as per expectation.
The output is as expected.

2.
If target (device/EVM) execution output for a given network is not matching with the corresponding host/pc emulation output, then user should follow below steps to identify the first layer having mismatch:
Check if input to the network itself is mismatching then this indicates mismatch during pre-processing.
There is no difference between the inputs. This has been confirmed by saving the pre-processed tensor/np.array using np.save both in the docker as well as on the target device.
3.
Enable layer level fixed point traces in both host emulation and EVM execution. This can be done by setting debug_level = 3
Next I generated traces with debug_level=3 set both in docker and on target device.
4.
Use any binary comparison tool (e.g. beyond compare, diff, cmp etc) to compare the traces_ref and traces_target folder
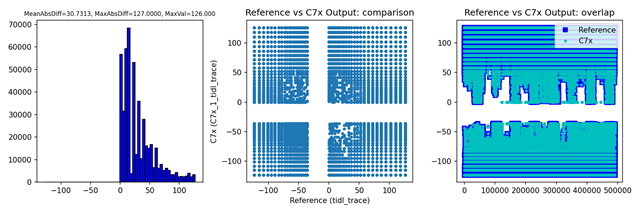
Next I used diff and cmp to compare these traces.
Further I plotted values from both traces against each other.
The layers that differ are:
tidl_trace_subgraph_1_0089_0001_0001_00001_00256_00001x00001.y
tidl_trace_subgraph_2_0162_0001_0001_00001_00008_00320x00192.y
tidl_trace_subgraph_2_0164_0001_0001_00001_00008_00320x00192.y
tidl_trace_subgraph_2_0166_0001_0001_00001_00008_00320x00192.y
tidl_trace_subgraph_2_0168_0001_0001_00001_00001_00320x00192.y
tidl_trace_subgraph_2_0170_0001_0001_00001_00001_00320x00192.y
tidl_trace_subgraph_2_0172_0001_0001_00001_00001_00320x00192_float.bin
 Layer SG2_0164
Layer SG2_0164
 Layer SG2_0166
Layer SG2_0166
 Layer SG2_0162
Layer SG2_0162
My question is what do I do next?
I am attaching my code and artifacts again in the hope that these comparison and the layers with mismatching traces may help you isolate the problem.
import copy
import time
import cv2
import numpy as np
from pathlib import Path
import glob
import re
import os
#from screen_grab import grab
class LoadImages: # for inference
def __init__(self, path, screen=1):
self.dev = False
self.grab_screen = False
p = str(Path(path).absolute()) # os-agnostic absolute path
print(p)
if '*' in p:
files = sorted(glob.glob(p, recursive=True)) # glob
elif os.path.isdir(p):
files = sorted(glob.glob(os.path.join(p, '*.*'))) # dir
elif os.path.isfile(p):
files = [p] # files
elif p.startswith("/dev/video"):
files = [p]
self.dev = True
# elif "screengrab" in p:
# files = [p]
# self.grab_screen = True
else:
raise Exception(f'ERROR: {p} does not exist')
img_formats = ['bmp', 'jpg', 'jpeg', 'png', 'tif', 'tiff', 'dng', 'webp', 'mpo'] # acceptable image suffixes
vid_formats = ['mov', 'avi', 'mp4', 'mpg', 'mpeg', 'm4v', 'wmv', 'mkv'] # acceptable video suffixes
images = [x for x in files if x.split('.')[-1].lower() in img_formats]
videos = [x for x in files if x.split('.')[-1].lower() in vid_formats]
if self.dev:
videos = [p]
ni, nv = len(images), len(videos)
self.files = images + videos
self.screen = screen
self.nf = ni + nv # number of files
self.video_flag = [False] * ni + [True] * nv
self.mode = 'image'
# if self.grab_screen:
# self.nf = 1
# self.video_flag = [False]
# self.files = [p]
if any(videos):
self.new_video(videos[0]) # new video
else:
self.cap = None
assert self.nf > 0, f'No images or videos found in {p}. ' \
f'Supported formats are:\nimages: {img_formats}\nvideos: {vid_formats}'
def __iter__(self):
self.count = 0
return self
def __next__(self):
if self.count == self.nf:
raise StopIteration
path = self.files[self.count]
if self.video_flag[self.count]:
# Read video
self.mode = 'video'
ret_val, img0 = self.cap.read()
if not ret_val:
self.count += 1
self.cap.release()
if self.count == self.nf: # last video
raise StopIteration
else:
path = self.files[self.count]
self.new_video(path)
ret_val, img0 = self.cap.read()
# if self.dev:
# if (cv2.waitKey(1) & 0xFF) == ord('q'):
# raise StopIteration
self.frame += 1
print(f'video {self.count + 1}/{self.nf} ({self.frame}/{self.nframes}) {path}: ', end='')
# elif self.grab_screen:
# self.mode = 'video'
# img0 = grab(self.screen)
# assert img0 is not None, 'Frame Error'
# if (cv2.waitKey(1) & 0xFF) == ord('q'):
# raise StopIteration
else:
# Read image
self.count += 1
img0 = cv2.imread(path) # BGR
assert img0 is not None, 'Image Not Found ' + path
#print(f'image {self.count}/{self.nf} {path}: ', end='')
# Padded resize
img0 = cv2.resize(img0, (1280,720), interpolation=cv2.INTER_LINEAR)
return path, img0, self.cap
def new_video(self, path):
self.frame = 0
self.cap = cv2.VideoCapture(path)
self.nframes = int(self.cap.get(cv2.CAP_PROP_FRAME_COUNT))
if self.dev:
self.nframes = 250
def __len__(self):
return self.nf # number of files
def increment_path(path, exist_ok=True, sep=''):
# Increment path, i.e. runs/exp --> runs/exp{sep}0, runs/exp{sep}1 etc.
path = Path(path) # os-agnostic
if (path.exists() and exist_ok) or (not path.exists()):
return str(path)
else:
dirs = glob.glob(f"{path}{sep}*") # similar paths
matches = [re.search(rf"%s{sep}(\d+)" % path.stem, d) for d in dirs]
i = [int(m.groups()[0]) for m in matches if m] # indices
n = max(i) + 1 if i else 2 # increment number
return f"{path}{sep}{n}" # update path
def letterbox(
img,
new_shape=(320, 320),
color=(114, 114, 114),
auto=True,
scaleFill=False,
scaleup=True,
stride=32,
):
# Resize and pad image while meeting stride-multiple constraints
shape = img.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup: # only scale down, do not scale up (for better test mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[
1] # wh padding
if auto: # minimum rectangle
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[
0] # width, height ratios
# divide padding into 2 sides
dw /= 2
dh /= 2
if shape[::-1] != new_unpad: # resize
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
img = cv2.copyMakeBorder(
img,
top,
bottom,
left,
right,
cv2.BORDER_CONSTANT,
value=color,
) # add border
return img, ratio, (dw, dh)
def _make_grid(nx=20, ny=20):
xv, yv = np.meshgrid(np.arange(0, nx), np.arange(0, ny))
return np.stack((xv, yv), 2).reshape((1, 1, ny, nx, 2)).astype('float32')
def _sigmoid(arr):
arr = np.array(arr, dtype=np.float32)
return 1.0 / (1.0 + np.exp(-1.0 * arr))
def split_for_trace_model(pred=None, anchor_grid=None):
z = []
st = [8, 16, 32]
for i in range(3):
bs, _, ny, nx = pred[i].shape
pred[i] = pred[i].reshape(bs, 3, 85, ny, nx).transpose(0, 1, 3, 4, 2)
y = _sigmoid(pred[i])
gr = _make_grid(nx, ny)
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + gr) * st[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2)**2 * anchor_grid[i] # wh
z.append(y.reshape(bs, -1, 85))
pred = np.concatenate(z, 1)
return pred
def _xywh2xyxy(x):
# Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2]
# where xy1=top-left, xy2=bottom-right
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def _box_iou(box1, box2):
# https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
"""
Return intersection-over-union (Jaccard index) of boxes.
Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
Arguments:
box1 (Tensor[N, 4])
box2 (Tensor[M, 4])
Returns:
iou (Tensor[N, M]): the NxM matrix containing the pairwise
IoU values for every element in boxes1 and boxes2
"""
def box_area(box):
# box = 4xn
return (box[2] - box[0]) * (box[3] - box[1])
area1 = box_area(box1.T)
area2 = box_area(box2.T)
# inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
inter = (np.minimum(box1[:, None, 2:], box2[:, 2:]) -
np.maximum(box1[:, None, :2], box2[:, :2])).clamp(0).prod(2)
return inter / (area1[:, None] + area2 - inter
) # iou = inter / (area1 + area2 - inter)
def _nms(boxes, scores, iou_threshold):
x1, y1 = boxes[:, 0], boxes[:, 1]
x2, y2 = boxes[:, 2], boxes[:, 3]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= iou_threshold)[0]
order = order[inds + 1]
result = np.stack(keep)
return result
def non_max_suppression(
prediction,
conf_thres=0.25,
iou_thres=0.45,
multi_label=False,
labels=(),
):
"""Runs Non-Maximum Suppression (NMS) on inference results
Returns:
list of detections, on (n,6) tensor per image [xyxy, conf, cls]
"""
nc = prediction.shape[2] - 5 # number of classes
xc = prediction[..., 4] > conf_thres # candidates
# Settings
max_det = 300 # maximum number of detections per image
max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
time_limit = 10.0 # seconds to quit after
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
t = time.time()
output = [np.zeros((0, 6))] * prediction.shape[0]
for xi, x in enumerate(prediction): # image index, image inference
# Apply constraints
x = x[xc[xi]] # confidence
# Cat apriori labels if autolabelling
if labels and len(labels[xi]):
l = labels[xi]
v = np.zeros((len(l), nc + 5), device=x.device)
v[:, :4] = l[:, 1:5] # box
v[:, 4] = 1.0 # conf
v[range(len(l)), l[:, 0].long() + 5] = 1.0 # cls
x = np.concatenate((x, v), 0)
# If none remain process next image
if not x.shape[0]:
continue
# Compute conf
x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
# Box (center x, center y, width, height) to (x1, y1, x2, y2)
box = _xywh2xyxy(x[:, :4])
# Detections matrix nx6 (xyxy, conf, cls)
if multi_label:
i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).T
x = np.concatenate((box[i], x[i, j + 5, None], j[:, None].float()),
1)
else: # best class only
conf = np.max(x[:, 5:], axis=1, keepdims=True)
j = np.argmax(x[:, 5:], axis=1)
j = j.reshape((j.shape[0], 1))
x = np.concatenate((box, conf, j.astype('float32')),
1)[conf.reshape(-1) > conf_thres]
# Check shape
n = x.shape[0] # number of boxes
if not n: # no boxes
continue
elif n > max_nms: # excess boxes
x = x[x[:, 4].argsort(
descending=True)[:max_nms]] # sort by confidence
# NMS
boxes, scores = x[:, :4], x[:, 4] # boxes (offset by class), scores
i = _nms(
boxes,
scores,
iou_thres,
)
if i.shape[0] > max_det: # limit detections
i = i[:max_det]
output[xi] = x[i]
if (time.time() - t) > time_limit:
print(f'WARNING: NMS time limit {time_limit}s exceeded')
break # time limit exceeded
return output
def scale_coords(img1_shape, coords, img0_shape, ratio_pad=None):
# Rescale coords (xyxy) from img1_shape to img0_shape
if ratio_pad is None: # calculate from img0_shape
gain = min(img1_shape[0] / img0_shape[0],
img1_shape[1] / img0_shape[1]) # gain = old / new
pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (
img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
else:
gain = ratio_pad[0][0]
pad = ratio_pad[1]
coords[:, [0, 2]] -= pad[0] # x padding
coords[:, [1, 3]] -= pad[1] # y padding
coords[:, :4] /= gain
_clip_coords(coords, img0_shape)
return coords
def _clip_coords(boxes, img_shape):
# Clip bounding xyxy bounding boxes to image shape (height, width)
boxes[:, 0] = np.clip(boxes[:, 0], 0, img_shape[1]) # x1
boxes[:, 1] = np.clip(boxes[:, 1], 0, img_shape[0]) # y1
boxes[:, 2] = np.clip(boxes[:, 2], 0, img_shape[1]) # x2
boxes[:, 3] = np.clip(boxes[:, 3], 0, img_shape[0]) # y1
def driving_area_mask(seg, pad_wh=None):
if pad_wh is None:
return 1.0 - seg[0][0]
else:
temp_seg = copy.deepcopy(seg[0][0])
pad_w = int(pad_wh[0])
pad_h = int(pad_wh[1])
seg_width = int(temp_seg.shape[1])
seg_height = int(temp_seg.shape[0])
temp_seg = temp_seg[pad_h:seg_height - pad_h, pad_w:seg_width - pad_w]
return 1.0 - temp_seg
def lane_line_mask(ll, pad_wh=None):
if pad_wh is None:
return ll[0][0]
else:
temp_ll = copy.deepcopy(ll[0][0])
pad_w = int(pad_wh[0])
pad_h = int(pad_wh[1])
seg_width = int(temp_ll.shape[1])
seg_height = int(temp_ll.shape[0])
temp_ll = temp_ll[pad_h:seg_height - pad_h, pad_w:seg_width - pad_w]
return temp_ll
import os
import copy
import time
import argparse
import cv2
import numpy as np
import onnxruntime
from pathlib import Path
from utils_onnx import increment_path, LoadImages
import shutil
import platform
from common_utils import *
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument(
'--video',
type=str,
default='sample.mp4',
)
parser.add_argument(
"-c", "--compile",
action="store_true",
help="Run in Model compilation mode"
)
parser.add_argument(
"-d", "--disable_offload",
action="store_true",
help="Disable offload to TIDL"
)
parser.add_argument(
'--model',
type=str,
default='weight/YOLOPv2.onnx',
)
parser.add_argument(
'--score_th',
type=float,
default=0.3,
)
parser.add_argument(
'--nms_th',
type=float,
default=0.45,
)
parser.add_argument(
'--save',
action='store_true',
help='save images/videos'
)
parser.add_argument(
'--source',
type=str,
default='sample.mp4',
help='input source'
)
parser.add_argument(
'--project',
default='runs/detect',
help='save results to project/name'
)
parser.add_argument(
'--name',
default='exp',
help='save results to project/name'
)
parser.add_argument(
'--exist-ok',
action='store_true',
help='existing project/name ok, do not increment'
)
parser.add_argument(
'--screen',
type=int,
default=1,
help='Screen number you want to use for capturing'
)
parser.add_argument(
'--log',
type=int,
default=2,
help='Log severity level.0:Verbose, 1:Info, 2:Warning. 3:Error, 4:Fatal.'
)
parser.add_argument("--debug", type=int, default=0, help="Debug info level 0,1,2,3")
parser.add_argument('--cal-iter', type=int, default=50, help='Number of iterations for calibration')
args = parser.parse_args()
return args
def run_inference(
onnx_session,
image,
score_th,
nms_th,
):
input_image = copy.deepcopy(image)
input_image, _, (pad_w, pad_h) = utils_onnx.letterbox(input_image)
# BGR→RGB
input_image = input_image[:, :, ::-1].transpose(2, 0, 1)
# PyTorch Tensor
input_image = np.ascontiguousarray(input_image)
input_image = input_image.astype('float32')
input_image /= 255.0
# NCHW
input_image = np.expand_dims(input_image, axis=0)
np.save('npy_inputs_outputs/input_dock.npy', input_image)
input_details = onnx_session.get_inputs()
input_name = input_details[0].name
input_shape = input_details[0].shape
results = onnx_session.run(None, {input_name: input_image})
np.save('npy_inputs_outputs/output_dock.npy', np.array(results, dtype=object))
result_dets = []
result_dets.append(results[0][0])
result_dets.append(results[0][1])
result_dets.append(results[0][2])
anchor_grid = []
anchor_grid.append(results[1])
anchor_grid.append(results[2])
anchor_grid.append(results[3])
result_dets = utils_onnx.split_for_trace_model(
result_dets,
anchor_grid,
)
result_dets = utils_onnx.non_max_suppression(
result_dets,
conf_thres=score_th,
iou_thres=nms_th,
)
bboxes = []
scores = []
class_ids = []
for result_det in result_dets:
if len(result_det) > 0:
result_det[:, :4] = utils_onnx.scale_coords(
input_image.shape[2:],
result_det[:, :4],
image.shape,
).round()
for *xyxy, score, class_id in reversed(result_det):
x1, y1 = xyxy[0], xyxy[1]
x2, y2 = xyxy[2], xyxy[3]
bboxes.append([int(x1), int(y1), int(x2), int(y2)])
scores.append(float(score))
class_ids.append(int(class_id))
result_road_seg = utils_onnx.driving_area_mask(
results[4],
(pad_w, pad_h),
)
result_lane_seg = utils_onnx.lane_line_mask(
results[5],
(pad_w, pad_h),
)
return (bboxes, scores, class_ids), result_road_seg, result_lane_seg
def main():
args = get_args()
# Enforce compilation on x86 only
if platform.machine() == "aarch64" and args.compile == True:
print(
"Compilation of models is only supported on x86 machine \n\
Please do the compilation on PC and copy artifacts for running on TIDL devices "
)
exit(-1)
source = args.source
screen = args.screen
save_img = args.save # save inference images
if save_img:
save_dir = Path(increment_path(Path(args.project) / args.name, exist_ok=args.exist_ok)) # increment run
save_dir.mkdir(parents=True, exist_ok=True) # make save_dir
video_path = args.video
model_path = args.model
score_th = args.score_th
nms_th = args.nms_th
c7x_firmware_version = "11_00_00_00" #set variable for firmware version.
compile_options = {}
compile_options.update(optional_options)
so = onnxruntime.SessionOptions()
so.log_severity_level = args.log
compile_options['artifacts_folder'] = 'custom-artifacts/yolopv2'
compile_options['tidl_tools_path'] = os.environ.get("TIDL_TOOLS_PATH")
# compile_options['advanced_options:c7x_firmware_version'] = c7x_firmware_version
compile_options['advanced_options:calibration_frames'] = 25
compile_options['advanced_options:calibration_iterations'] = args.cal_iter
compile_options['debug_level'] = args.debug
print(f"compile_options: {compile_options}")
calib_images = os.listdir('calib-imgs')
if args.compile:
import onnx
os.makedirs(compile_options["artifacts_folder"], exist_ok=True)
for root, dirs, files in os.walk(
compile_options["artifacts_folder"], topdown=False
):
[os.remove(os.path.join(root, f)) for f in files]
[os.rmdir(os.path.join(root, d)) for d in dirs]
EP_list = ['TIDLCompilationProvider', 'CPUExecutionProvider']
# Shape inference needed for offload to C7x
onnx.shape_inference.infer_shapes_path(
model_path, model_path
)
onnx_session = onnxruntime.InferenceSession(
model_path,
providers=EP_list,
provider_options=[compile_options, {}],
sess_options=so
)
print(f"EP: {onnx_session.get_providers()}")
elif args.disable_offload:
EP_list = ['CPUExecutionProvider']
onnx_session = onnxruntime.InferenceSession(
model_path,
providers=EP_list,
sess_options=so
)
print(f"EP: {onnx_session.get_providers()}")
else:
EP_list = ['TIDLExecutionProvider', 'CPUExecutionProvider']
onnx_session = onnxruntime.InferenceSession(
model_path,
providers=EP_list,
provider_options=[compile_options, {}],
sess_options=so
)
print(f"EP: {onnx_session.get_providers()}")
vid_path, vid_writer = None, None
dataset = LoadImages(source, screen=screen)
#video_capture = cv2.VideoCapture(video_path)
for path, frame, vid_cap in dataset:
start_time = time.time()
# ret, frame = video_capture.read()
# if not ret:
# break
(bboxes, scores, class_ids), road_seg, lane_seg = run_inference(
onnx_session,
frame,
score_th,
nms_th,
)
fps = 1 / (time.time() - start_time)
debug_image = draw_debug_image(
frame,
(bboxes, scores, class_ids),
road_seg,
lane_seg,
fps,
)
if not args.compile:
# Image height and width are needed for drawing mid points on the image prepared from all the results of seg, lanes, boxes
img_height, img_width, _ = debug_image.shape
if seg_mid:
draw_seg_mid(debug_image, img_height, img_width, start, seg_mid, end)
if mid_lls:
draw_ll_mid(debug_image, img_height, img_width, mid_lls)
# cv2.imshow("YOLOPv2", debug_image)
# key = cv2.waitKey(1)
# if key == 27: # ESC
# break
out_pipeline = "appsrc ! videoconvert ! kmssink driver-name=tidss sync=false"
# Save image/video with segments, lanes and mid points shown. Not relevant for inference though.
if save_img:
p = Path(path)
save_path = str(save_dir / p.name) # img.jpg
if dataset.mode == 'image':
cv2.imwrite(save_path, debug_image)
print(f" The image with the result is saved in: {save_path}")
else: # 'video' or 'stream'
if vid_path != save_path: # new video
vid_path = save_path
if isinstance(vid_writer, cv2.VideoWriter):
vid_writer.release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
#w = int(video_capture.get(cv2.CAP_PROP_FRAME_WIDTH))
#h = int(video_capture.get(cv2.CAP_PROP_FRAME_HEIGHT))
w,h = debug_image.shape[1], debug_image.shape[0]
else: # stream
fps, w, h = 30, debug_image.shape[1], debug_image.shape[0]
save_path += '.mp4'
vid_writer = cv2.VideoWriter(out_pipeline, cv2.CAP_GSTREAMER, 0, fps, (w, h))
vid_writer.write(debug_image)
# video_capture.release()
# cv2.destroyAllWindows()
def draw_debug_image(
image,
car_dets,
road_seg,
lane_seg,
fps,
):
debug_image = copy.deepcopy(image)
image_width, image_height = debug_image.shape[1], debug_image.shape[0]
road_mask = np.stack((road_seg, ) * 3, axis=-1).astype('float32')
road_mask = cv2.resize(
road_mask,
dsize=(image_width, image_height),
interpolation=cv2.INTER_LINEAR,
)
road_mask = np.where(road_mask > 0.5, 0, 1)
bg_image = np.zeros(debug_image.shape, dtype=np.uint8)
bg_image[:] = [0, 255, 0]
road_mask_image = np.where(road_mask, debug_image, bg_image)
debug_image = cv2.addWeighted(debug_image, 0.5, road_mask_image, 0.5, 1.0)
road_mask = np.stack((lane_seg, ) * 3, axis=-1).astype('float32')
road_mask = cv2.resize(
road_mask,
dsize=(image_width, image_height),
interpolation=cv2.INTER_LINEAR,
)
road_mask = np.where(road_mask > 0.5, 0, 1)
bg_image = np.zeros(debug_image.shape, dtype=np.uint8)
bg_image[:] = [0, 0, 255]
road_mask_image = np.where(road_mask, debug_image, bg_image)
debug_image = cv2.addWeighted(debug_image, 0.5, road_mask_image, 0.5, 1.0)
for bbox, score, class_id in zip(*car_dets):
cv2.rectangle(
debug_image,
pt1=(bbox[0], bbox[1]),
pt2=(bbox[2], bbox[3]),
color=(0, 255, 255),
thickness=2,
)
# text = '%s:%s' % (str(class_id), '%.2f' % score)
# cv2.putText(
# debug_image,
# text,
# (bbox[0], bbox[1] - 10),
# cv2.FONT_HERSHEY_SIMPLEX,
# 0.7,
# color=(0, 255, 255),
# thickness=2,
# )
cv2.putText(
debug_image,
"FPS:" + '{:.1f}'.format(fps),
(10, 30),
cv2.FONT_HERSHEY_SIMPLEX,
0.8,
(255, 0, 0),
2,
cv2.LINE_AA,
)
return debug_image
if __name__ == "__main__":
main()
# Copyright (c) 2018-2024, Texas Instruments
# All Rights Reserved.
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions are met:
#
# * Redistributions of source code must retain the above copyright notice, this
# list of conditions and the following disclaimer.
#
# * Redistributions in binary form must reproduce the above copyright notice,
# this list of conditions and the following disclaimer in the documentation
# and/or other materials provided with the distribution.
#
# * Neither the name of the copyright holder nor the names of its
# contributors may be used to endorse or promote products derived from
# this software without specific prior written permission.
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
import os
import sys
import platform
import numpy as np
from PIL import Image, ImageFont, ImageDraw, ImageEnhance
import yaml
import shutil
import json
from config_utils import *
if platform.machine() == "aarch64":
numImages = 100
else:
import requests
import onnx
numImages = 3
current = os.path.dirname(os.path.realpath(__file__))
parent = os.path.dirname(os.path.dirname(current))
sys.path.append(parent)
try:
from osrt_model_tools.tflite_tools import tflite_model_opt as tflOpt
except ImportError:
pass
try:
from osrt_model_tools.onnx_tools.tidl_onnx_model_utils import (
onnx_model_opt as onnxOpt,
)
except ImportError:
pass
from caffe2onnx.src.load_save_model import loadcaffemodel, saveonnxmodel
from caffe2onnx.src.caffe2onnx import Caffe2Onnx
from caffe2onnx.src.args_parser import parse_args
from caffe2onnx.src.utils import freeze
artifacts_folder = "../../../model-artifacts/"
output_images_folder = "../../../output_images/"
output_binary_folder = "../../../output_binaries/"
tensor_bits = 8
debug_level = 0
max_num_subgraphs = 16
accuracy_level = 1
calibration_frames = 2
calibration_iterations = 5
output_feature_16bit_names_list = "" # "conv1_2, fire9/concat_1"
params_16bit_names_list = "" # "fire3/squeeze1x1_2"
mixed_precision_factor = -1
quantization_scale_type = 0
high_resolution_optimization = 0
pre_batchnorm_fold = 1
inference_mode = 0
num_cores = 1
ti_internal_nc_flag = 1601
data_convert = 3
SOC = os.environ["SOC"]
if quantization_scale_type == 3:
data_convert = 0
# set to default accuracy_level 1
activation_clipping = 1
weight_clipping = 1
bias_calibration = 1
channel_wise_quantization = 0
tidl_tools_path = os.environ.get("TIDL_TOOLS_PATH")
# custom_layers_list_name = "125"
# enable_custom_layers = 1
optional_options = {
# "priority":0,
# delay in ms
# "max_pre_empt_delay":10
"platform": "J7",
"version": "7.2",
"tensor_bits": tensor_bits,
"debug_level": debug_level,
"max_num_subgraphs": max_num_subgraphs,
"deny_list": "", # "MaxPool"
"deny_list:layer_type": "",
"deny_list:layer_name": "",
"model_type": "", # OD
"accuracy_level": accuracy_level,
"advanced_options:calibration_frames": calibration_frames,
"advanced_options:calibration_iterations": calibration_iterations,
"advanced_options:output_feature_16bit_names_list": output_feature_16bit_names_list,
"advanced_options:params_16bit_names_list": params_16bit_names_list,
"advanced_options:mixed_precision_factor": mixed_precision_factor,
"advanced_options:quantization_scale_type": quantization_scale_type,
# "advanced_options:enable_custom_layers":enable_custom_layers,
# "advanced_options:custom_layers_list_name":custom_layers_list_name
# "object_detection:meta_layers_names_list" : meta_layers_names_list, -- read from models_configs dictionary below
# "object_detection:meta_arch_type" : meta_arch_type, -- read from models_configs dictionary below
"advanced_options:high_resolution_optimization": high_resolution_optimization,
"advanced_options:pre_batchnorm_fold": pre_batchnorm_fold,
"ti_internal_nc_flag": ti_internal_nc_flag,
# below options will be read only if accuracy_level = 9, else will be discarded.... for accuracy_level = 0/1, these are preset internally
"advanced_options:activation_clipping": activation_clipping,
"advanced_options:weight_clipping": weight_clipping,
"advanced_options:bias_calibration": bias_calibration,
"advanced_options:add_data_convert_ops": data_convert,
"advanced_options:channel_wise_quantization": channel_wise_quantization,
# Advanced options for SOC 'am69a'
"advanced_options:inference_mode": inference_mode,
"advanced_options:num_cores": num_cores,
}
modelzoo_path = "../../../../../../jacinto-ai-modelzoo/models"
modelforest_path = "../../../../../../jacinto-ai-modelforest/models"
lables = "../../../test_data/labels.txt"
models_base_path = "../../../models/public/"
model_artifacts_base_path = "../../../model-artifacts/"
def get_dataset_info(task_type, num_classes):
categories = [dict(id=catagory_id+1, supercategory=task_type, name=f"category_{catagory_id+1}") for catagory_id in range(num_classes)]
dataset_info = dict(info=dict(description=f'{task_type} dataset'),
categories=categories,
color_map=get_color_palette(num_classes))
return dataset_info
def gen_param_yaml(artifacts_folder_path, config, new_height, new_width):
resize = []
crop = []
resize.append(new_width)
resize.append(new_height)
crop.append(new_width)
crop.append(new_height)
if config["task_type"] == "classification":
model_type = "classification"
elif config["task_type"] == "detection":
model_type = "detection"
elif config["task_type"] == "segmentation":
model_type = "segmentation"
model_file = config["task_type"].split("/")[0]
dict_file = dict()
layout = config["preprocess"]["data_layout"]
if config["session"]["session_name"] == "tflitert":
layout = "NHWC"
config["preprocess"]["data_layout"] = layout
model_file_name = os.path.basename(config["session"]["model_path"])
model_path = config["session"]["model_path"]
model_name = model_path.split("/")[-1]
config["preprocess"]["add_flip_image"] = False
config["session"]["artifacts_folder"] = "artifacts"
config["session"]["model_path"] = "model/" + model_name
config["session"]["input_data_layout"] = layout
config["session"]["target_device"] = SOC.upper()
if config["task_type"] == "detection":
if config["extra_info"]["label_offset_type"] == "80to90":
config["postprocess"]["label_offset_pred"] = coco_det_label_offset_80to90(
label_offset=config["extra_info"]["label_offset"]
)
else:
config["postprocess"]["label_offset_pred"] = coco_det_label_offset_90to90(
label_offset=config["extra_info"]["label_offset"]
)
if isinstance(config["preprocess"]["crop"], int):
config["preprocess"]["crop"] = (
config["preprocess"]["crop"],
config["preprocess"]["crop"],
)
if isinstance(config["preprocess"]["resize"], int):
config["preprocess"]["resize"] = (
config["preprocess"]["resize"],
config["preprocess"]["resize"],
)
param_dict = pretty_object(config)
param_dict.pop("source")
param_dict.pop("extra_info")
dataset_info = get_dataset_info(config["task_type"], config["extra_info"]["num_classes"])
artifacts_model_path = "/".join(artifacts_folder_path.split("/")[:-1])
artifacts_model_path_yaml = os.path.join(artifacts_model_path, "param.yaml")
with open(artifacts_model_path_yaml, "w") as file:
yaml.safe_dump(param_dict, file, sort_keys=False)
dataset_path_yaml = os.path.join(artifacts_model_path, "dataset.yaml")
with open(dataset_path_yaml, "w") as dataset_fp:
yaml.safe_dump(dataset_info, dataset_fp, sort_keys=False)
headers = {
"User-Agent": "My User Agent 1.0",
"From": "aid@ti.com", # This is another valid field
}
def get_url_from_link_file(url):
if url.endswith(".link"):
r = requests.get(url, allow_redirects=True, headers=headers)
url = r.content.rstrip()
return url
def download_model(models_configs, model_name):
model_artifacts_path = model_artifacts_base_path + model_name + "/model"
if not os.path.isdir(model_artifacts_path):
os.makedirs(model_artifacts_path)
if model_name in models_configs.keys():
model_path = models_configs[model_name]["session"]["model_path"]
if "source" in models_configs[model_name].keys():
model_source = models_configs[model_name]["source"]
if not os.path.isfile(model_path):
# Check whether the specified path exists or not
if not os.path.exists(os.path.dirname(model_path)):
# Create a new directory because it does not exist
os.makedirs(os.path.dirname(model_path))
if (
"original_model_type"
in models_configs[model_name]["extra_info"].keys()
) and models_configs[model_name]["extra_info"][
"original_model_type"
] == "caffe":
print("Downloading ", model_source["prototext"])
r = requests.get(
get_url_from_link_file(model_source["model_url"]),
allow_redirects=True,
headers=headers,
)
open(model_source["prototext"], "wb").write(r.content)
print("Downloading ", model_source["caffe_model"])
r = requests.get(
get_url_from_link_file(model_source["caffe_model_url"]),
allow_redirects=True,
headers=headers,
)
open(model_source["caffe_model"], "wb").write(r.content)
graph, params = loadcaffemodel(
model_source["prototext"], model_source["caffe_model"]
)
c2o = Caffe2Onnx(graph, params, model_path)
onnxmodel = c2o.createOnnxModel()
freeze(onnxmodel)
saveonnxmodel(onnxmodel, model_path)
else:
print("Downloading ", model_path)
r = requests.get(
get_url_from_link_file(model_source["model_url"]),
allow_redirects=True,
headers=headers,
)
open(model_path, "wb").write(r.content)
filename = os.path.splitext(model_path)
abs_path = os.path.realpath(model_path)
input_mean = models_configs[model_name]["session"]["input_mean"]
input_scale = models_configs[model_name]["session"]["input_scale"]
if models_configs[model_name]["session"]["input_optimization"] == True:
if filename[-1] == ".onnx":
onnxOpt.tidlOnnxModelOptimize(
abs_path, abs_path, input_scale, input_mean
)
elif filename[-1] == ".tflite":
tflOpt.tidlTfliteModelOptimize(
abs_path, abs_path, input_scale, input_mean
)
if (filename[-1] == ".onnx") and (
models_configs[model_name]["source"]["infer_shape"] == True
):
onnx.shape_inference.infer_shapes_path(model_path, model_path)
if "meta_layers_names_list" in models_configs[model_name]["session"].keys():
meta_layers_names_list = models_configs[model_name]["session"][
"meta_layers_names_list"
]
if meta_layers_names_list is not None and not os.path.isfile(
meta_layers_names_list
):
print("Downloading ", meta_layers_names_list)
r = requests.get(
get_url_from_link_file(model_source["meta_arch_url"]),
allow_redirects=True,
headers=headers,
)
open(meta_layers_names_list, "wb").write(r.content)
shutil.copy(meta_layers_names_list, model_artifacts_path)
shutil.copy(model_path, model_artifacts_path)
else:
print(
f"{model_name} ot found in availbale list of model configs - {models_configs.keys()}"
)
def load_labels(filename):
with open(filename, "r") as f:
return [line.strip() for line in f.readlines()]
def get_class_labels(output, org_image_rgb):
output = np.squeeze(np.float32(output))
source_img = org_image_rgb.convert("RGBA")
draw = ImageDraw.Draw(source_img)
outputoffset = 0 if (output.shape[0] == 1001) else 1
top_k = output.argsort()[-5:][::-1]
labels = load_labels(lables)
for j, k in enumerate(top_k):
curr_class = f"\n {j} {output[k]:08.6f} {labels[k+outputoffset]} \n"
classes = classes + curr_class if ("classes" in locals()) else curr_class
draw.text((0, 0), classes, fill="red")
source_img = source_img.convert("RGB")
classes = classes.replace("\n", ",")
return (classes, source_img)
colors_list = [
(255, 0, 0),
(0, 255, 0),
(0, 0, 255),
(255, 255, 0),
(0, 255, 255),
(255, 0, 255),
(255, 64, 0),
(64, 255, 0),
(64, 0, 255),
(255, 255, 64),
(64, 255, 255),
(255, 64, 255),
(196, 128, 0),
(128, 196, 0),
(128, 0, 196),
(196, 196, 128),
(128, 196, 196),
(196, 128, 196),
(64, 128, 0),
(128, 64, 0),
(128, 0, 64),
(196, 0, 0),
(196, 64, 64),
(64, 196, 64),
(64, 255, 64),
(64, 64, 255),
(255, 64, 64),
(128, 255, 128),
(128, 128, 255),
(255, 128, 128),
(196, 64, 196),
(196, 196, 64),
(64, 196, 196),
(196, 255, 196),
(196, 196, 255),
(196, 196, 128),
]
def mask_transform(inp):
colors = np.asarray(colors_list)
inp = np.squeeze(inp)
colorimg = np.zeros((inp.shape[0], inp.shape[1], 3), dtype=np.float32)
height, width = inp.shape
inp = np.rint(inp)
inp = inp.astype(np.uint8)
for y in range(height):
for x in range(width):
if inp[y][x] < 22:
colorimg[y][x] = colors[inp[y][x]]
inp = colorimg.astype(np.uint8)
return inp
def RGB2YUV(rgb):
m = np.array(
[
[0.29900, -0.16874, 0.50000],
[0.58700, -0.33126, -0.41869],
[0.11400, 0.50000, -0.08131],
]
)
yuv = np.dot(rgb, m)
yuv[:, :, 1:] += 128.0
rgb = np.clip(yuv, 0.0, 255.0)
return yuv
def YUV2RGB(yuv):
m = np.array(
[
[1.0, 1.0, 1.0],
[-0.000007154783816076815, -0.3441331386566162, 2.0320025777816772],
[1.14019975662231445, -0.5811380310058594, 0.00001542569043522235],
]
)
yuv[:, :, 1:] -= 128.0
rgb = np.dot(yuv, m)
rgb = np.clip(rgb, 0.0, 255.0)
return rgb
def seg_mask_overlay(output_data, org_image_rgb):
classes = ""
output_data = np.squeeze(output_data)
if output_data.ndim > 2:
output_data = output_data.argmax(axis=2)
# output_data = output_data.argmax(axis=0) #segformer
output_data = np.squeeze(output_data)
mask_image_rgb = mask_transform(output_data)
org_image = RGB2YUV(org_image_rgb)
mask_image = RGB2YUV(mask_image_rgb)
org_image[:, :, 1] = mask_image[:, :, 1]
org_image[:, :, 2] = mask_image[:, :, 2]
blend_image = YUV2RGB(org_image)
blend_image = blend_image.astype(np.uint8)
blend_image = Image.fromarray(blend_image).convert("RGB")
return (classes, blend_image)
def det_box_overlay(outputs, org_image_rgb, od_type, framework=None):
classes = ""
source_img = org_image_rgb.convert("RGBA")
draw = ImageDraw.Draw(source_img)
# mmdet
if framework == "MMDetection":
outputs = [np.squeeze(output_i) for output_i in outputs]
if len(outputs[0].shape) == 2:
num_boxes = int(outputs[0].shape[0])
for i in range(num_boxes):
if outputs[0][i][4] > 0.3:
xmin = outputs[0][i][0]
ymin = outputs[0][i][1]
xmax = outputs[0][i][2]
ymax = outputs[0][i][3]
print(outputs[1][i])
draw.rectangle(
((int(xmin), int(ymin)), (int(xmax), int(ymax))),
outline=colors_list[int(outputs[1][i]) % len(colors_list)],
width=2,
)
elif len(outputs[0].shape) == 1:
num_boxes = 1
for i in range(num_boxes):
if outputs[i][4] > 0.3:
xmin = outputs[i][0]
ymin = outputs[i][1]
xmax = outputs[i][2]
ymax = outputs[i][3]
draw.rectangle(
((int(xmin), int(ymin)), (int(xmax), int(ymax))),
outline=colors_list[int(outputs[1]) % len(colors_list)],
width=2,
)
# SSD
elif od_type == "SSD":
outputs = [np.squeeze(output_i) for output_i in outputs]
num_boxes = int(outputs[0].shape[0])
for i in range(num_boxes):
if outputs[2][i] > 0.3:
xmin = outputs[0][i][0]
ymin = outputs[0][i][1]
xmax = outputs[0][i][2]
ymax = outputs[0][i][3]
draw.rectangle(
(
(int(xmin * source_img.width), int(ymin * source_img.height)),
(int(xmax * source_img.width), int(ymax * source_img.height)),
),
outline=colors_list[int(outputs[1][i]) % len(colors_list)],
width=2,
)
# yolov5
elif od_type == "YoloV5":
outputs = [np.squeeze(output_i) for output_i in outputs]
num_boxes = int(outputs[0].shape[0])
for i in range(num_boxes):
if outputs[0][i][4] > 0.3:
xmin = outputs[0][i][0]
ymin = outputs[0][i][1]
xmax = outputs[0][i][2]
ymax = outputs[0][i][3]
draw.rectangle(
((int(xmin), int(ymin)), (int(xmax), int(ymax))),
outline=colors_list[int(outputs[0][i][5]) % len(colors_list)],
width=2,
)
elif (
od_type == "HasDetectionPostProcLayer"
): # model has detection post processing layer
for i in range(int(outputs[3][0])):
if outputs[2][0][i] > 0.1:
ymin = outputs[0][0][i][0]
xmin = outputs[0][0][i][1]
ymax = outputs[0][0][i][2]
xmax = outputs[0][0][i][3]
draw.rectangle(
(
(int(xmin * source_img.width), int(ymin * source_img.height)),
(int(xmax * source_img.width), int(ymax * source_img.height)),
),
outline=colors_list[int(outputs[1][0][i]) % len(colors_list)],
width=2,
)
elif (
od_type == "EfficientDetLite"
): # model does not have detection post processing layer
for i in range(int(outputs[0].shape[1])):
if outputs[0][0][i][5] > 0.3:
ymin = outputs[0][0][i][1]
xmin = outputs[0][0][i][2]
ymax = outputs[0][0][i][3]
xmax = outputs[0][0][i][4]
print(outputs[0][0][i][6])
draw.rectangle(
((int(xmin), int(ymin)), (int(xmax), int(ymax))),
outline=colors_list[int(outputs[0][0][i][6]) % len(colors_list)],
width=2,
)
source_img = source_img.convert("RGB")
return (classes, source_img)
Due to file size I am unable to attach my generated artifacts as well as the ONNX model file. Is there some alternative way to send them to you? (During earlier posts I was able to upload these)
Regards,
Charanjit Singh

