


Hi,
We are having problems with the performance on our GPMC bus. I recently posted a similar question regarding access speed in general, and we are now wondering if this sets an absolute limit for our throughout using GPMC.
This is the former post:
http://e2e.ti.com/support/arm/sitara_arm/f/791/t/331214.aspx
We are doing consecutive reads to an FPGA connected to the GPMC bus. We are alternating between data an status register which means we can't do burst reads.
The GPMC module is therefore configured to do single byte reads using the following parameters:
WRAPBURST 0 READMULTIPLE 0 READTYPE 1 WRITEMULTIPLE 0 WRITETYPE 1 CLKACTIVATIONTIME 0 ATTACHEDDEVICEPAGELENGTH 0 WAITREADMONITORIN 0 WAITWRITEMONITORING 0 WAITMONITORINGTIME 0 WAITPINSELECT 0 DEVICESIZE 0 DEVICETYPE 0 MUXADDDATA 0 TIMEPARAGRANULARITY 0 GPMCFCLKDIVIDER 1 CSWROFFTIME 5 CSRDOFFTIME 11 CSEXTRADELAY 0 CSONTIME 1 ADVAADMUXWROFFTIME 0 ADVAADMUXRDOFFTIME 0 ADVWROFFTIME 3 ADVRDOFFTIME 3 ADVEXTRADELAY 0 ADVAADMUXONTIME 0 ADVONTIME 1 WEOFFTIME 5 WEEXTRADELAY 0 WEONTIME 1 OEAADMUXOFFTIME 0 OEOFFTIME 11 OEEXTRADELAY 0 OEAADMUXONTIME 0 OEONTIME 4 PAGEBURSTACCESSTIME 0 RDACCESSTIME 10 WRCYCLETIME 5 RDCYCLETIME 11 WRACCESSTIME 0 WRDATAONADMUXBU 0 CYCLE2CYCLEDELAY 0 CYCLE2CYCLESAMECSEN 0 CYCLE2CYCLEDIFFCSEN 0 BUSTURNAROUND 0
Above, the read operation is configured to 11 100-Mhz cycles. The chip select is configured to be held low on the last 10 of those.
On the oscilloscope we can see that the chip select is being held low for exactly 100ns as seen below.
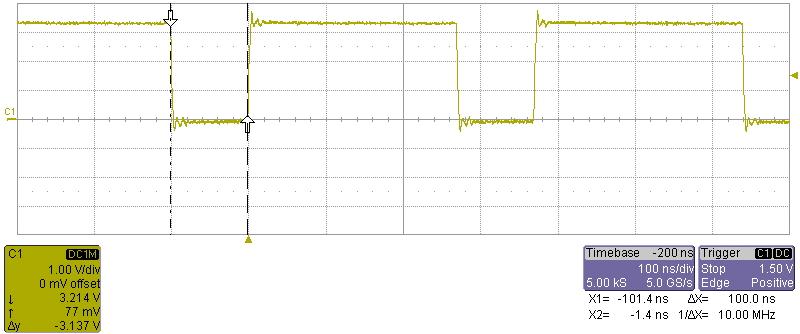
The problem is the long delay until next read. After the chip select goes high at the end of the read cycle, there is a delay of 260ns before the next read cycle starts, giving us a maximum speed of 370ns/byte.
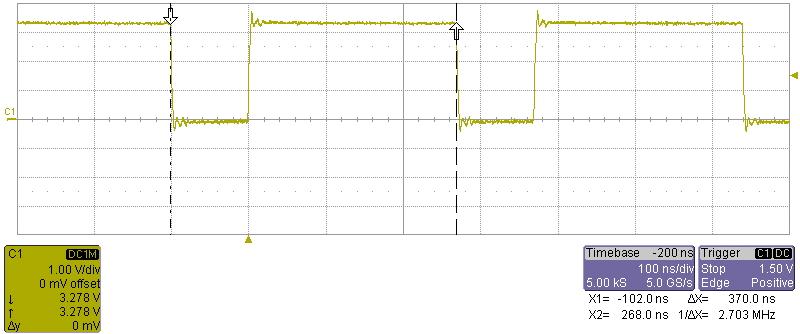
The above test is made from u-boot. An objdump of the code reads:
val = GPMC_READ(reg);
80103824: e5d32000 ldrb r2, [r3]
val = GPMC_READ(reg);
80103828: e5d32000 ldrb r2, [r3]
val = GPMC_READ(reg);
8010382c: e5d32000 ldrb r2, [r3]
val = GPMC_READ(reg);
80103830: e5d32000 ldrb r2, [r3]
val = GPMC_READ(reg);
80103834: e5d32000 ldrb r2, [r3]
Since the FPGA doesn't care about the clock, I have noticed that I can cut 20ns by setting the read type to 0 (async), but it is still to slow.
Is this the best performace we can hope for, due to delays on the internal interconnects?
Thank you for your time,
Rickard Åberg



