Hi,
I have posted an issue of packet loss in Linux forum. But the issue is not in linux kernel, the real issue is packet missing at ARM CPU. So, I am moving the question to Keystone forum. Please find the copy of post from linux.
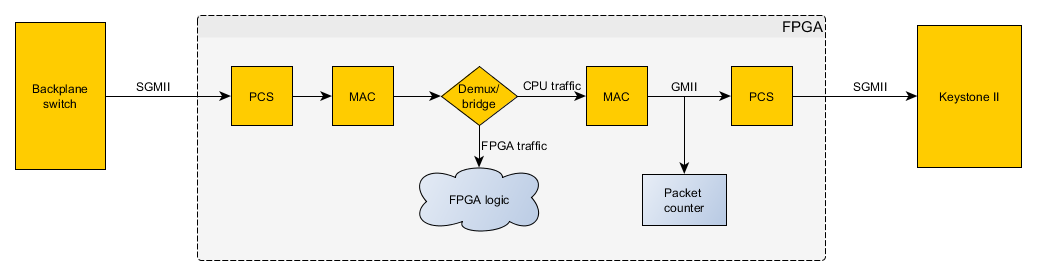
We are having custom board based on 66AK2H06. We are losing UDP packets between two custom boards. Port 0 is interfaced to FPGA which in turn is connected to backplane. The two custom boards talk to each other over backplane. One of the application from board 1 sends bursty traffic less than 50Mbps. We see that the packets are lost. There are no RcvBuf errors and InErrors reported in linux kernel.
No errors seen in CPSW statistics as seen by following command.
ethtool -S eth0
There are no drops seen in any of the socket Qs when observed using
cat /proc/net/udp.
We have a FPGA probe which monitors the sequence number of the packets for all the ports. When the packet loss happens, we do not see any packet lost until the FPGA nor in Linux. The packets are dropped somewhere between FPGA and CPU. Is that possible to get additional debug information on the switch statistics.
Is there any additional configuration required for CPSW ?
We are trying to send UDP traffic using iperf and the FPGA in Board 2 (Receiver Board) is probing the incoming UDP traffic on port 5001. The FPGA probe counter sees all the packets at the receiving end. But the packets are lost at CPU and not seen in Linux.
Please see below the log from iperf, netstat and FPGA probe.
~ $ iperf3 -c 192.168.0.104 -u -b 200M -l 1500 -p 5001
Connecting to host 192.168.0.104, port 5001
[ 4] local 192.168.0.102 port 58203 connected to 192.168.0.104 port 5001
[ ID] Interval Transfer Bandwidth Total Datagrams
[ 4] 0.00-1.00 sec 21.5 MBytes 181 Mbits/sec 15063
[ 4] 1.00-2.00 sec 24.9 MBytes 209 Mbits/sec 17426
[ 4] 2.00-3.00 sec 22.7 MBytes 191 Mbits/sec 15899
[ 4] 3.00-4.00 sec 25.4 MBytes 213 Mbits/sec 17760
[ 4] 4.00-5.00 sec 22.9 MBytes 192 Mbits/sec 16039
[ 4] 5.00-6.00 sec 25.3 MBytes 212 Mbits/sec 17656
[ 4] 6.00-7.00 sec 22.5 MBytes 189 Mbits/sec 15748
[ 4] 7.00-8.00 sec 23.9 MBytes 201 Mbits/sec 16739
[ 4] 8.00-9.00 sec 23.4 MBytes 197 Mbits/sec 16380
[ 4] 9.00-10.00 sec 23.5 MBytes 197 Mbits/sec 16435
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bandwidth Jitter Lost/Total Datagrams
[ 4] 0.00-10.00 sec 236 MBytes 198 Mbits/sec 0.022 ms 4096/165145 (2.5%)
[ 4] Sent 165145 datagrams
iperf Done.
################## Board 1 Receiver: ###############################
~ $ netstat.arm -s
Ip:
1421153 total packets received
0 forwarded
0 incoming packets discarded
1097051 incoming packets delivered
590165 requests sent out
173 fragments dropped after timeout
647641 reassemblies required
323539 packets reassembled ok
563 packet reassembles failed
Icmp:
67 ICMP messages received
0 input ICMP message failed.
InCsumErrors: 0
ICMP input histogram:
destination unreachable: 67
416 ICMP messages sent
0 ICMP messages failed
ICMP output histogram:
destination unreachable: 397
time exceeded: 19
IcmpMsg:
InType3: 67
OutType3: 397
OutType11: 19
Tcp:
5 active connections openings
6 passive connection openings
1 failed connection attempts
3 connection resets received
6 connections established
17357 segments received
20548 segments send out
0 segments retransmited
0 bad segments received.
1 resets sent
InCsumErrors: 0
Udp:
1053123 packets received
103635 packets to unknown port received.
0 packet receive errors
569302 packets sent
RcvbufErrors: 0
SndbufErrors: 0
InCsumErrors: 0
UdpLite:
InDatagrams: 0
NoPorts: 0
InErrors: 0
OutDatagrams: 0
RcvbufErrors: 0
SndbufErrors: 0
InCsumErrors: 0
error parsing /proc/net/snmp: Success
################# FPGA status ####################
Status 32769: "Packet loss monitor"
* Timestamp : 2015-09-10 14:01:46.614067
Packet cnt. : 165146