


Part Number: AM5728
Hi,
Depending on the number of executions of the code, GPMC read access is affected.
GPMC register is set as follows.
GPMC_CONFIG1_i 0x60 0x00601211
GPMC_CONFIG2_i 0x64 0x00090902
GPMC_CONFIG3_i 0x68 0x00010100
GPMC_CONFIG4_i 0x6C 0x06030903
GPMC_CONFIG5_i 0x70 0x00090A0A
GPMC_CONFIG6_i 0x74 0x86020281
GPMC_CONFIG7_i 0x78 0x00000F42
During GPMC read access,
When cortexA15 executes more than 40 instructions, 170ns delay occurs with GPMC access.
Why does this delay occur?
Please tell me how to solve the delay.
①call_16_read:
call_16_read:
ldrh r10, [r0] /* r0 = address on GMPC LSC0 */
ldrh r10, [r0]
ldrh r10, [r0]
ldrh r10, [r0]
ldrh r10, [r0]
ldrh r10, [r0]
ldrh r10, [r0]
ldrh r10, [r0]
ldrh r10, [r0]
ldrh r10, [r0]
bx lr
no instructions between gpmc reads -> no delay
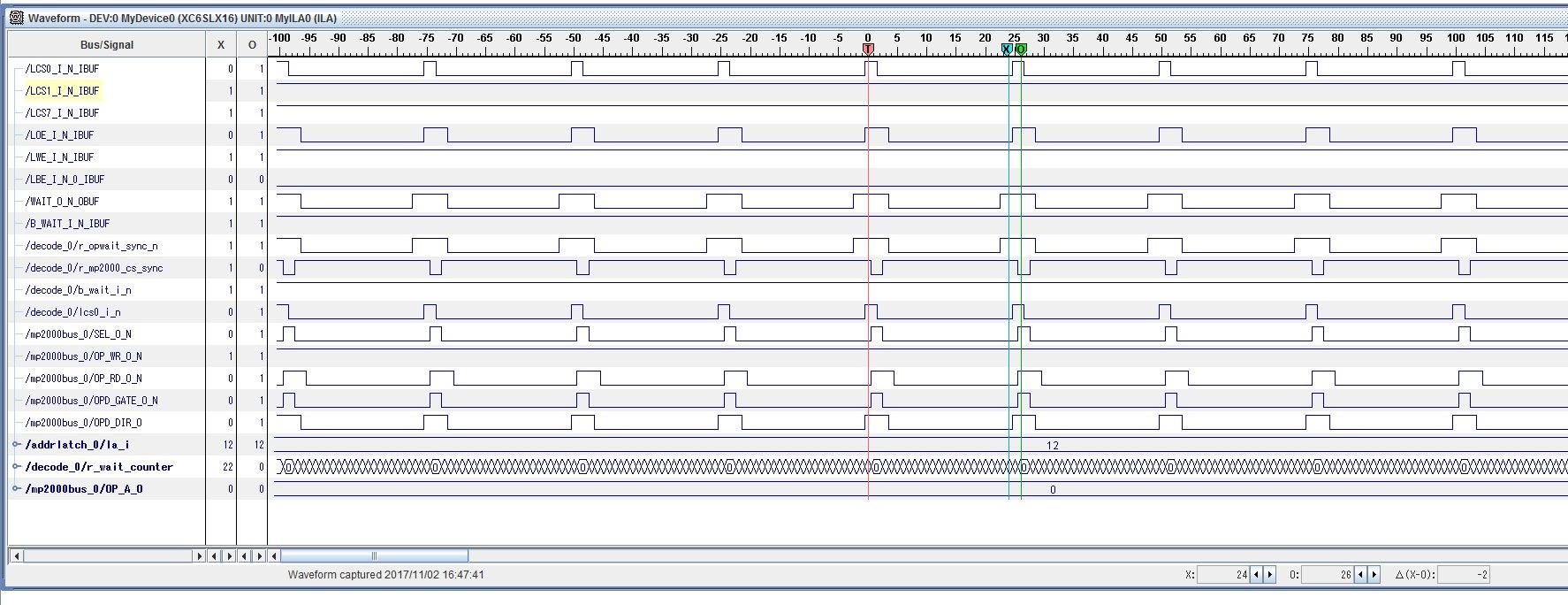
②call_16_read20:
ldrh r10, [r0] /* r0 = address on GMPC LSC0 */
ldrh r9, [r1] /* r1 = address on stack (will be in cach) */
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r10, [r0] /* r0 = address on GMPC LSC0 */
ldrh r10, [r0]
ldrh r10, [r0]
ldrh r10, [r0]
ldrh r10, [r0]
ldrh r10, [r0]
ldrh r10, [r0]
ldrh r10, [r0]
ldrh r10, [r0]
bx lr
Added 20 lines of instructions between gpmc reads -> no delay between accesses of added code
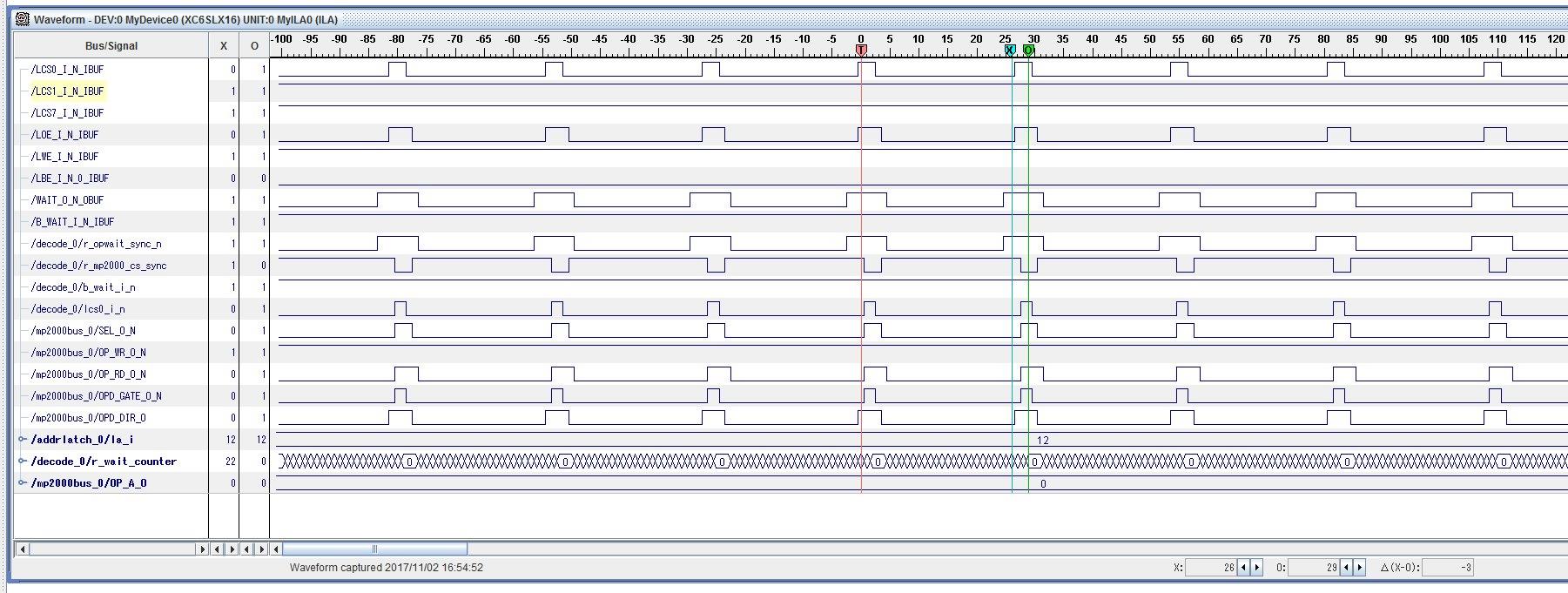
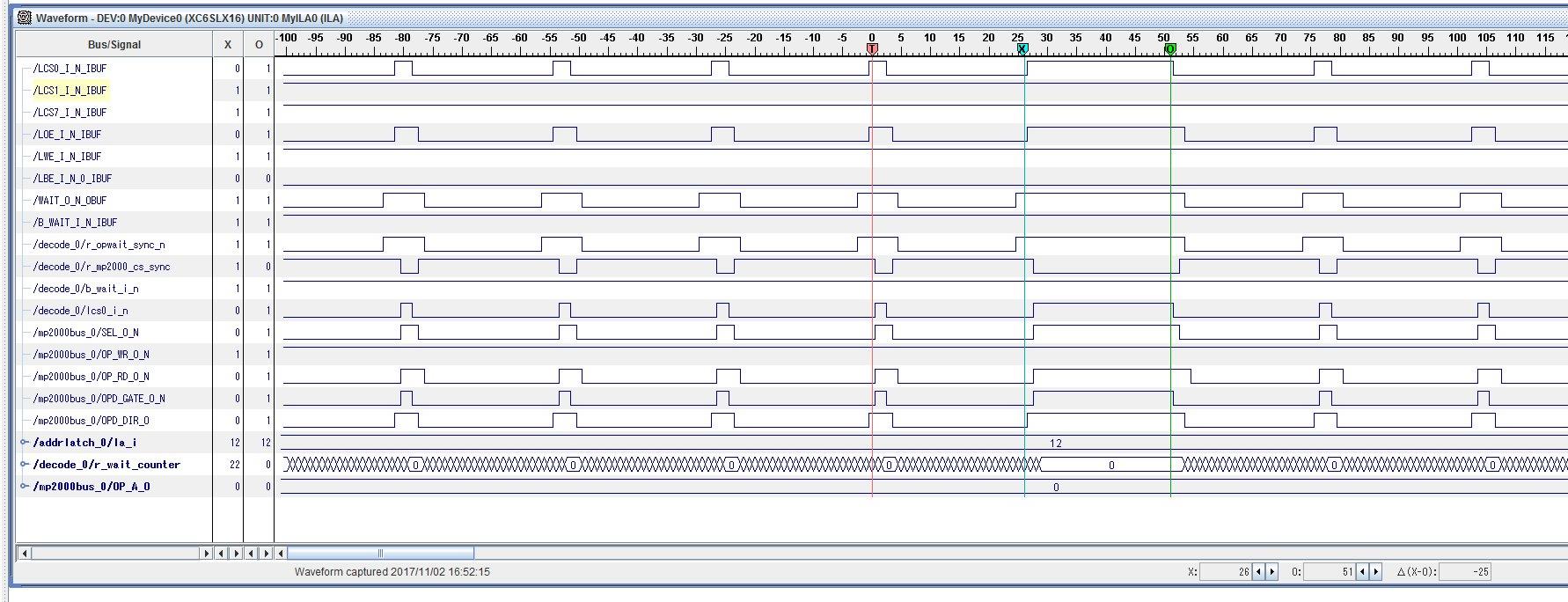
③call_16_read40:
call_16_read40:
ldrh r10, [r0] /* r0 = address on GMPC LSC0 */
ldrh r9, [r1] /* r1 = address on stack (will be in cach) */
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r9, [r1]
ldrh r10, [r0] /* r0 = address on GMPC LSC0 */
ldrh r10, [r0]
ldrh r10, [r0]
ldrh r10, [r0]
ldrh r10, [r0]
ldrh r10, [r0]
ldrh r10, [r0]
ldrh r10, [r0]
ldrh r10, [r0]
bx lr
Added 40 lines of instructions between gpmc reads -> 170ns delay between accesses of added code
Best Regards,
Shigehiro Tsuda


