Part Number: TDA2EXEVM
Hi ,
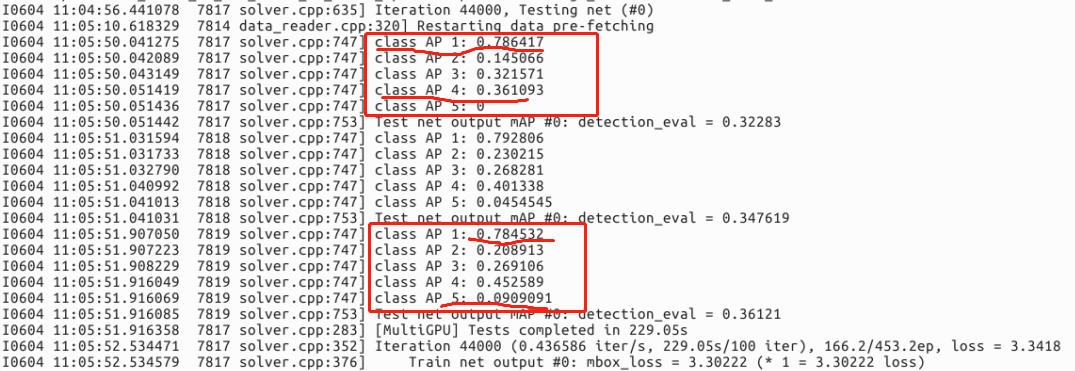
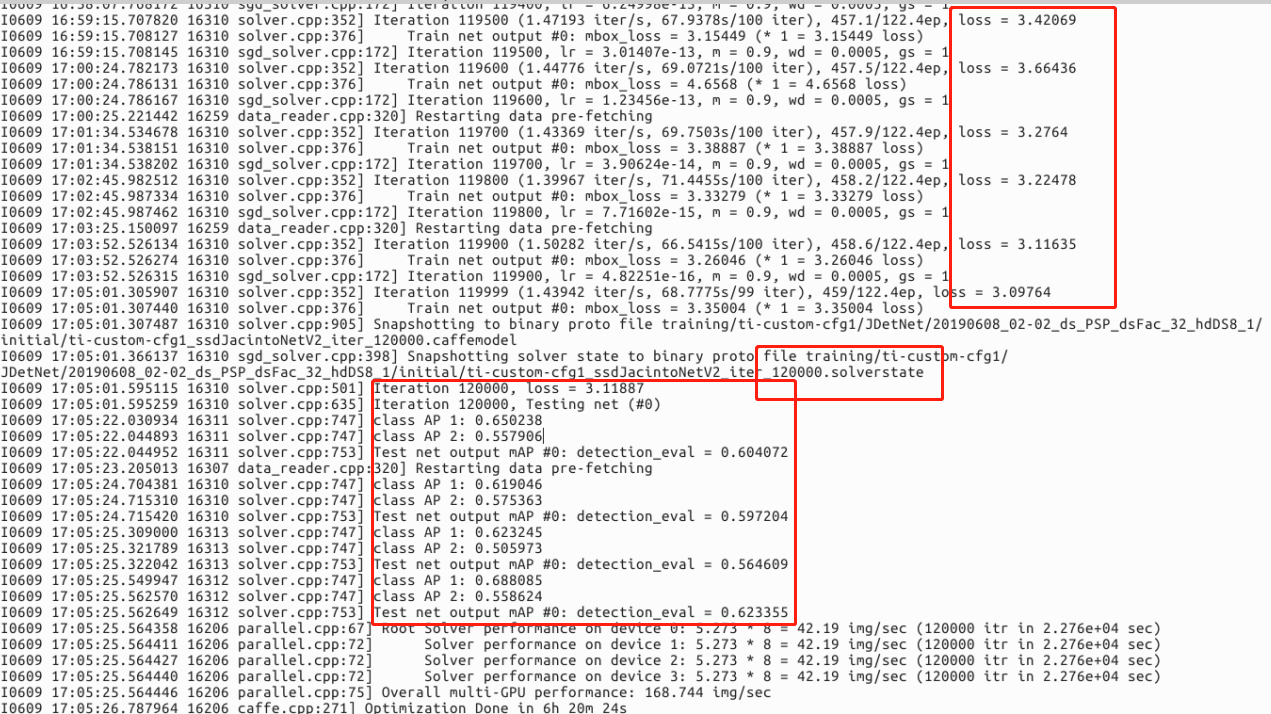
I am now have a dateset to train using the ssdJacintoNetV2 ,but the distribution of my data categories is very uneven,list as blow,
I want to kow How do I augment my sample in the dataset?

Can I crop different categories of data into different folders?And my train.txt and val.txt can support this style just like list blow without voc Pascal label?

Thank you very much!