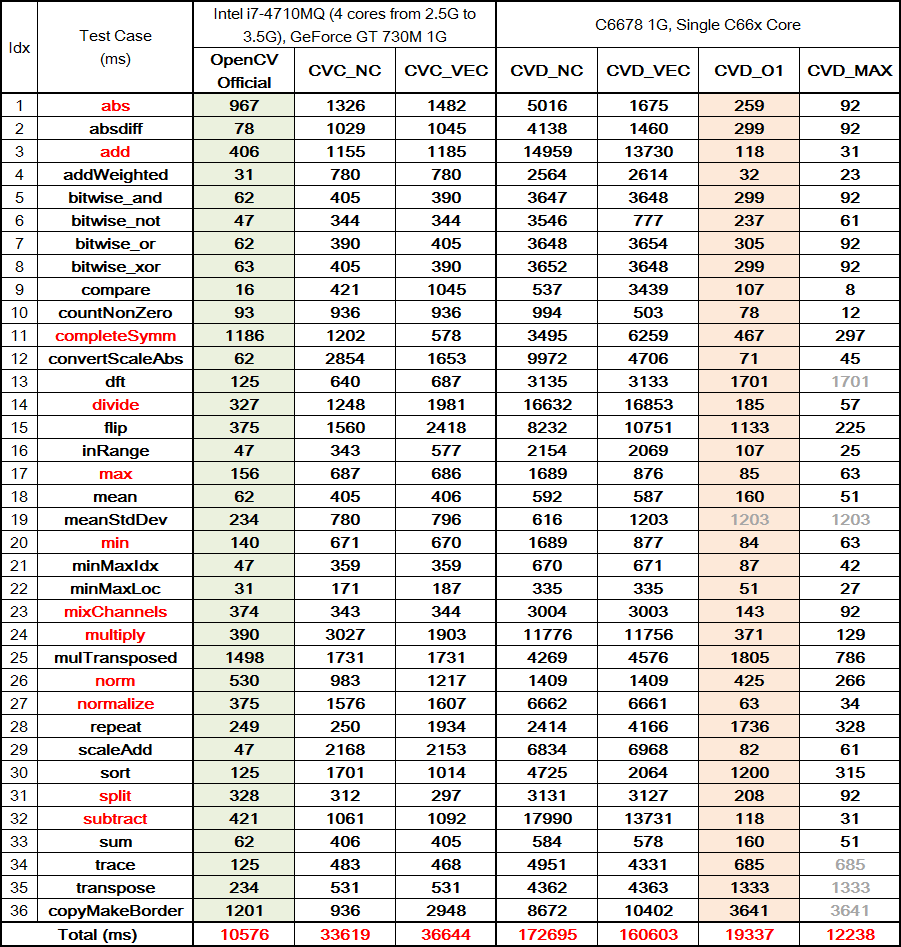
TI Experts-
We are porting OpenCV to C66x. We have replaced TI memory allocation functions with "smart malloc" and others that
allow us to conform with OpenCV (for example, control over alignment, use local mem or external mem depending on the
situation, etc), and we're using VLIB functions inside OpenCV functions to optimize where possible (with no change in
results).
In addition, we're optimizing key C/C++ codes, which is what my questions are about.
I had this original line of code, where pRowSrcf is a float pointer and pRowDstu is a uint8_t pointer (this line is
executed in a 'for' loop):
*pRowDstu++ = (uint8_t)*pRowSrcf++;
When the original line was replaced with below two lines as shown below:
int iVal = (int)*pRowSrcf++;
*pRowDstu++ = iVal;
there was a 10x increase in performance. I have attached the generated .asm code for each case and screenshot of replaced asm code. I think I understand what the compiler did here and why. My questions are:
-can this code be further optimized without resorting to hand asm coding ?
-currently the pointers are aligned to 4 bytes, would 16 bytes help ?
-is there a way to read four (4) floats at one time, convert into 4 uint8_t values, then store all 4 uint8_t bytes at once?
The reason this level of discussion is important is that copying images, with possible conversions of pixel data (both
numerical representation and pixel format), is fundamental to OpenCV -- such operations are everywhere in OpenCV
codes. I'm hoping to develop optimized methods embedded in a C++ class that I can add to opencv source and include in
the c66x branch on the opencv repository.
Thanks.
-Anish
HPC Engineer, Signalogic