

下記に掲載したexampleの Event_read() の速度性能が遅いので改造して、速度性能を調べました。
MCLK=24MHz、LDO_Vcore1、最適化設定なし の条件です。 測定値は目安としてお考えください。
MSP432 LPM0とLPM3のwait切り替えexample
** さらに、compiler optimaization 設定で大幅に性能改善した結果を、下記に追加いたしました。
1 EventLib改善
1.1 変更点
・ MSP432P401のIRQnはmax64(0~63)のため、eventを64バイトサーチ部分の時間がかかりすぎていました。
・ eventをビットに変更して、16bitsx4ビットを8bit単位のビットサーチに変更しました。
1.2 速度測定
・ IRQn:0~63 を16ビット単位でLSBからサーチするので、IRQn=15,31,47,63が長くかかります。
実際は、8bit単位に分割して速度upしてあります。
・ 3項添付のTest_event2を使用して、Event_read(irqn):IRQn:0~63を測定した結果は、6~11us、
eventなしは4usです。 これらがeventディスパッチのオーバヘッドになります。 (訂正:Dec.21.2016)
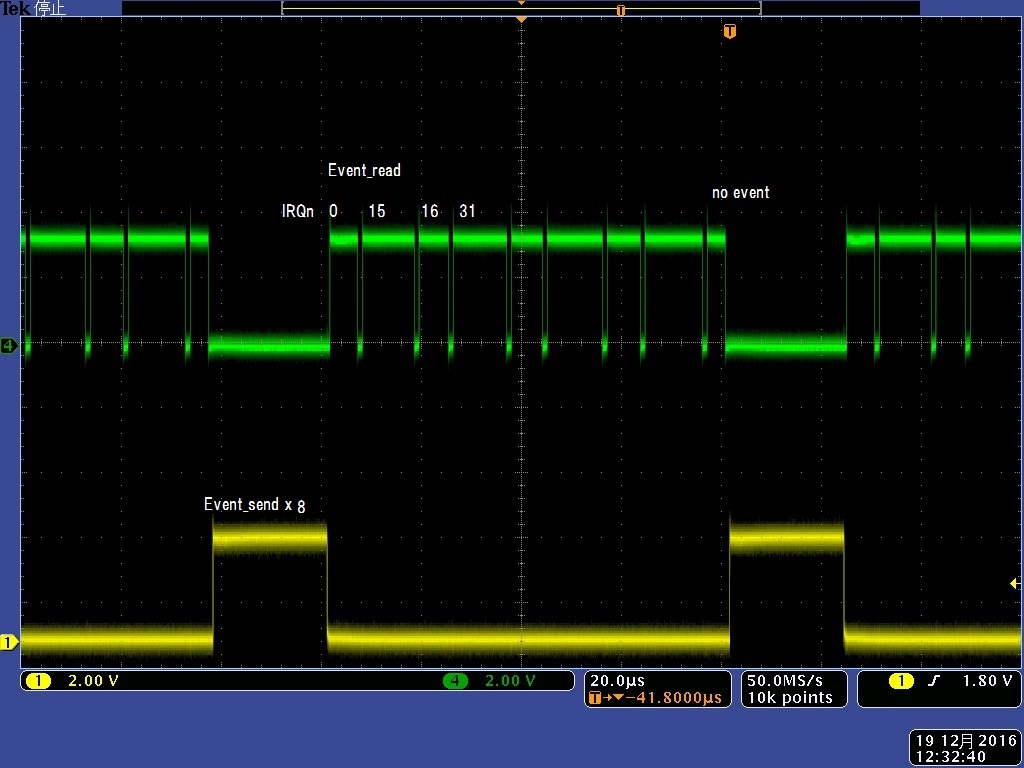
2 マルチイベントの動作
・ 3項添付の Event_lpm30_2で測定した結果です。
2.1 LPM3からのWake-up
・ LPM3ではFlash、SRAMなどのVCC供給が停止していますので、delayが生じます。
・ LPM3 sleepからWDT interruptでwake-upして、Event処理が再開されるまでのdelay 8usでした。

2.2 マルチイベントの測定結果
・ 複数ペリフェラルを並行動作させたときの、イベントディスパッチの速度を測定しました。
・ 処理の流れは、下記になります。
1) WDTの1秒割り込みでLPM3からwake-up
2) Event_readでWDT ISRイベントを見つけ、(switch文で)WDTブロックへ遷移
3) WDTブロックでは、TA0ブロックへEvent_sendでstart要求を送り、P5出力->P6へ割り込みを発生
4) Event_readでTA0イベントを見つけ、TA0ブロックへ遷移
5) TA0ブロックでは、LPM0要求をしてからTA0をstart
6) Event_readでP6 ISRイベントを見つけ、Port6ブロックに遷移
7) P6ブロックでP6IFG情報を受け取り
8) Event_readで、イベント無を検知し、LPM0(TA0が要求)でsleep
・ タイミングの実際は、3)->4)6)はイベントが重なって起きていますが、シーケンス処理になっています。
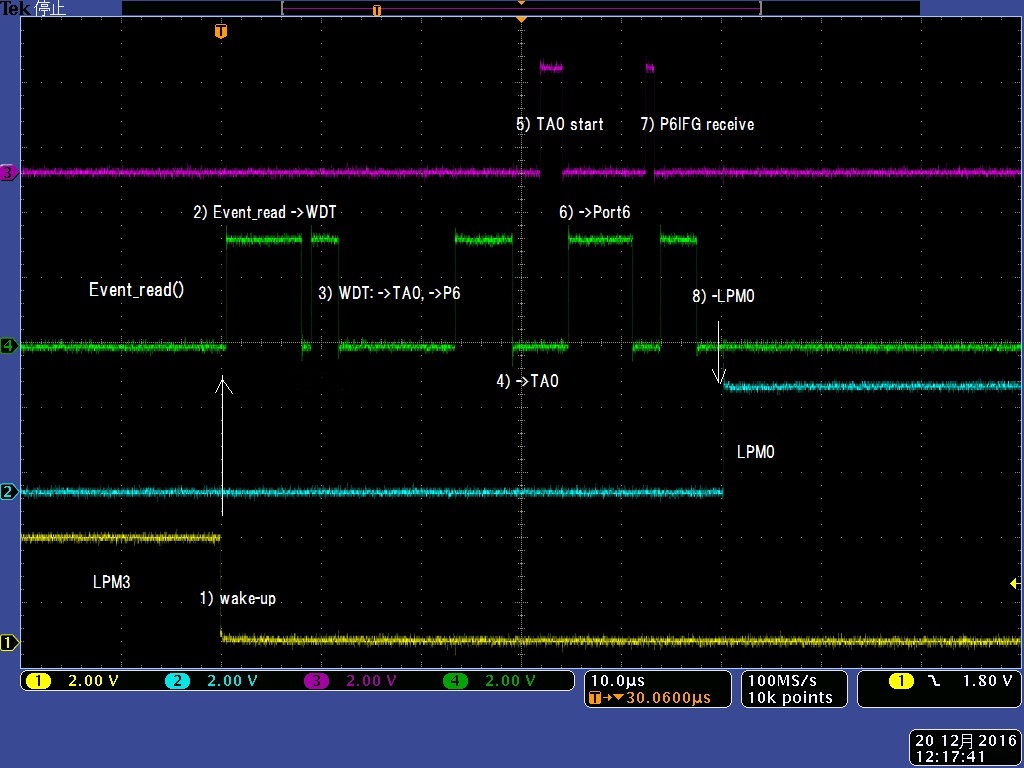
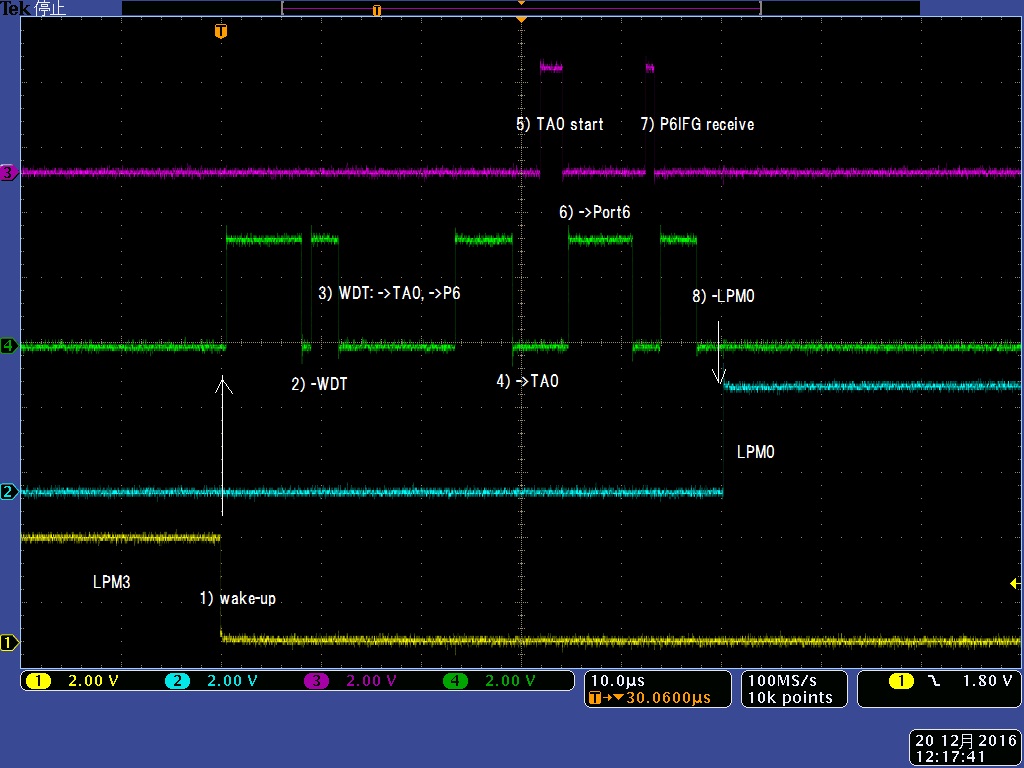{kind=link}
3 example