Other Parts Discussed in Thread: TDA4VM
Hi engineer:
Issue description:
we took LEO power solution (tps65941212+tps65941111) for TDA4VM in application. A fault happened occasionally that is the board will be stuck at 31mA during power on stage.
Root cause analysis:
Step1. Fault repeating
In order to repeat the fault quickly, we stopped feeding WDG 1s later after power up successfully, which means it has ~20 times fed WDG and then stop feeding WDG to warmly restart system periodically. Possibility is not certain, sometime it can repeat in several cycles, and sometimes it may happen in one day. Possibility is about one in 50 boards
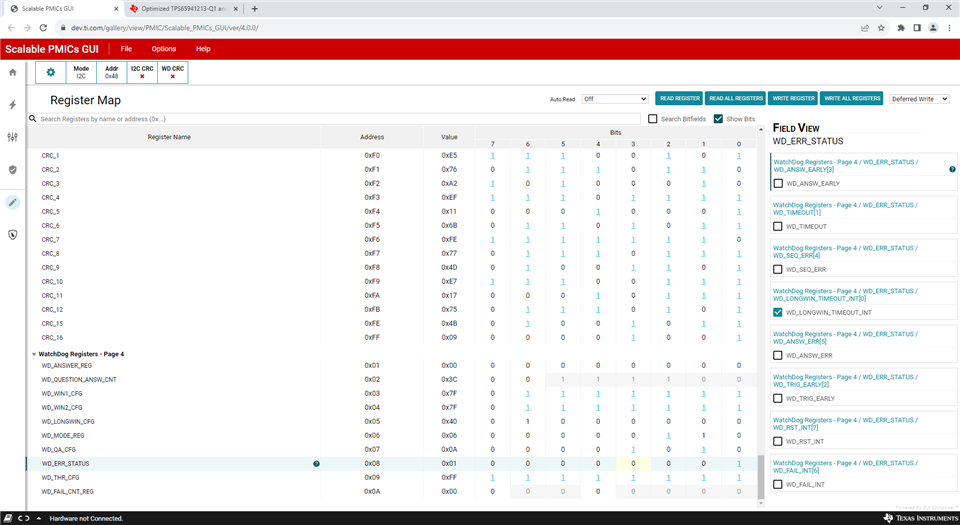
Step2. We checked registers values of PMICs as following when fault happened, and found that PMICs enter orderly shutdown mode, and SPMI_ERR_INT flag detected.
- PMIC-A
- INT_MISC (0x66)=00h
- INT_MODERATE_ERR (0x67)=08h
- INT_FSM_ERR (0x69)=82h
- PMIC-B:
- INT_MISC (0x66)=01h
- INT_MODERATE_ERR (0x67)=10h
- INT_FSM_ERR (0x69)=02h
Step3. Monitoring SPMI_SCLK/SPMI_DATA waveform with oscilloscope and found that it looks very good waveforms
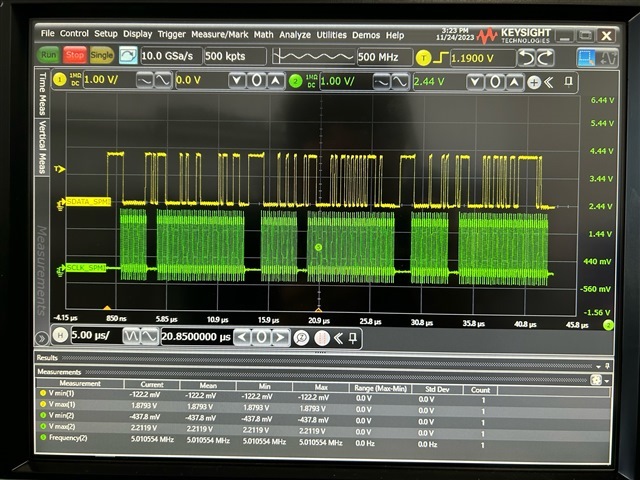
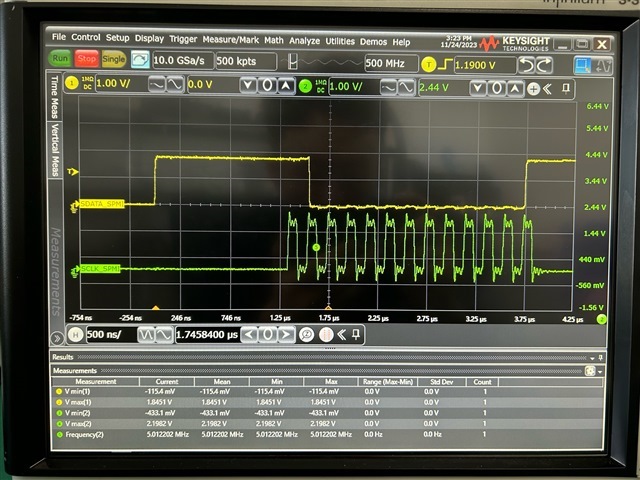
My question:
Why does the SPMI_ERR_INT flag happened? and what is root cause for my case?