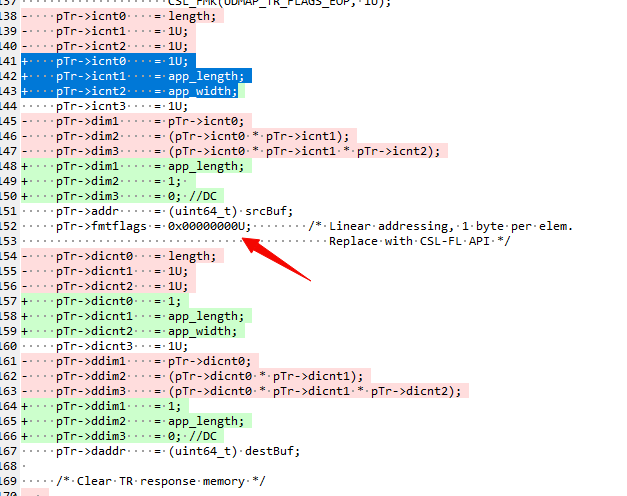
Hi all,
I want to use UDMA to transfer data and transpose data as shown below: Only the data in yellow need to be tranferred,
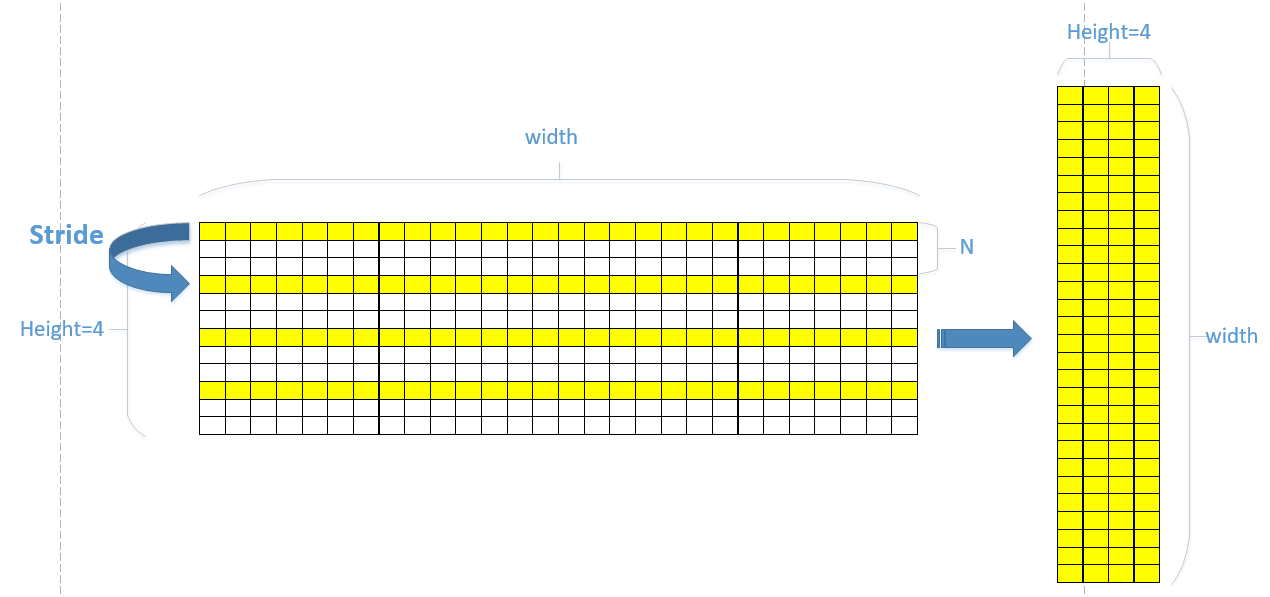
stride = width * N
And here is my configuration of UDMA TR:

But the UDMA stucked and never stop when I use this UDMA TR to transfer data.
Did I misconfigure something? Could you please provide me with a correct configuration to implement my idea?
Br,
Lance