This FAQ is no longer up-to-date. The arbitration delay information on this page should no longer be used as a reference.
For the latest information, refer to
[FAQ] PRU Read & Write Latencies
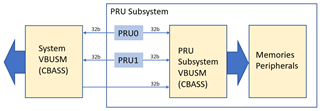
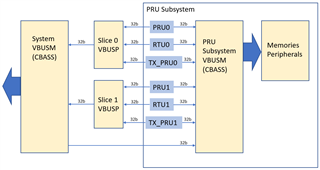
I am writing a PRU application for a PRU-ICSS device (AM335x, AM437x, AM57x), PRU-SS device (AM62x), or a PRU_ICSSG device (AM24x, AM64x, AM65x). I want to calculate how many clock cycles a read or a write will take. How do I do it?
This FAQ is an extension of the PRU Read Latencies app note. The app note will be updated with information from this FAQ at a later point in time.