Dear Champs,
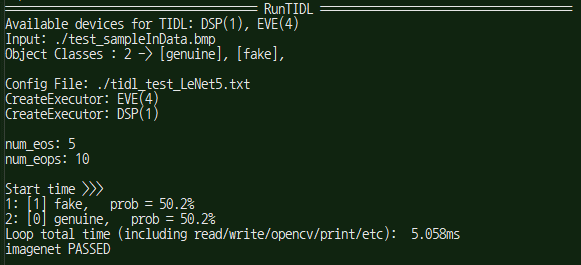
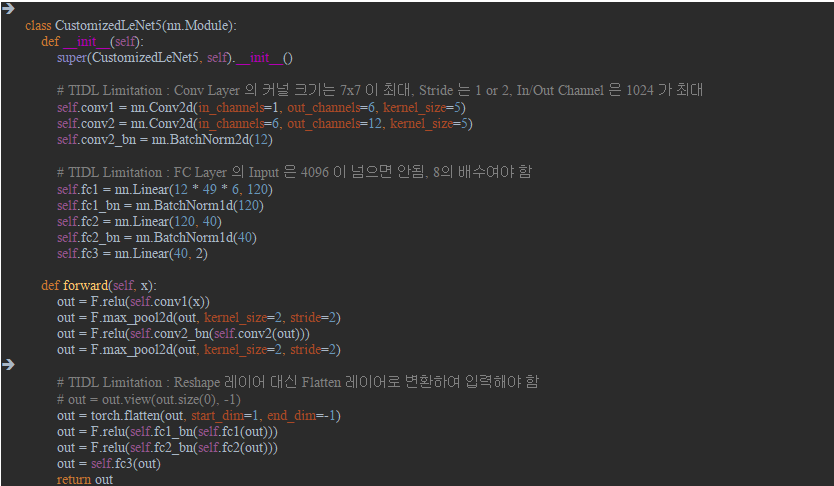
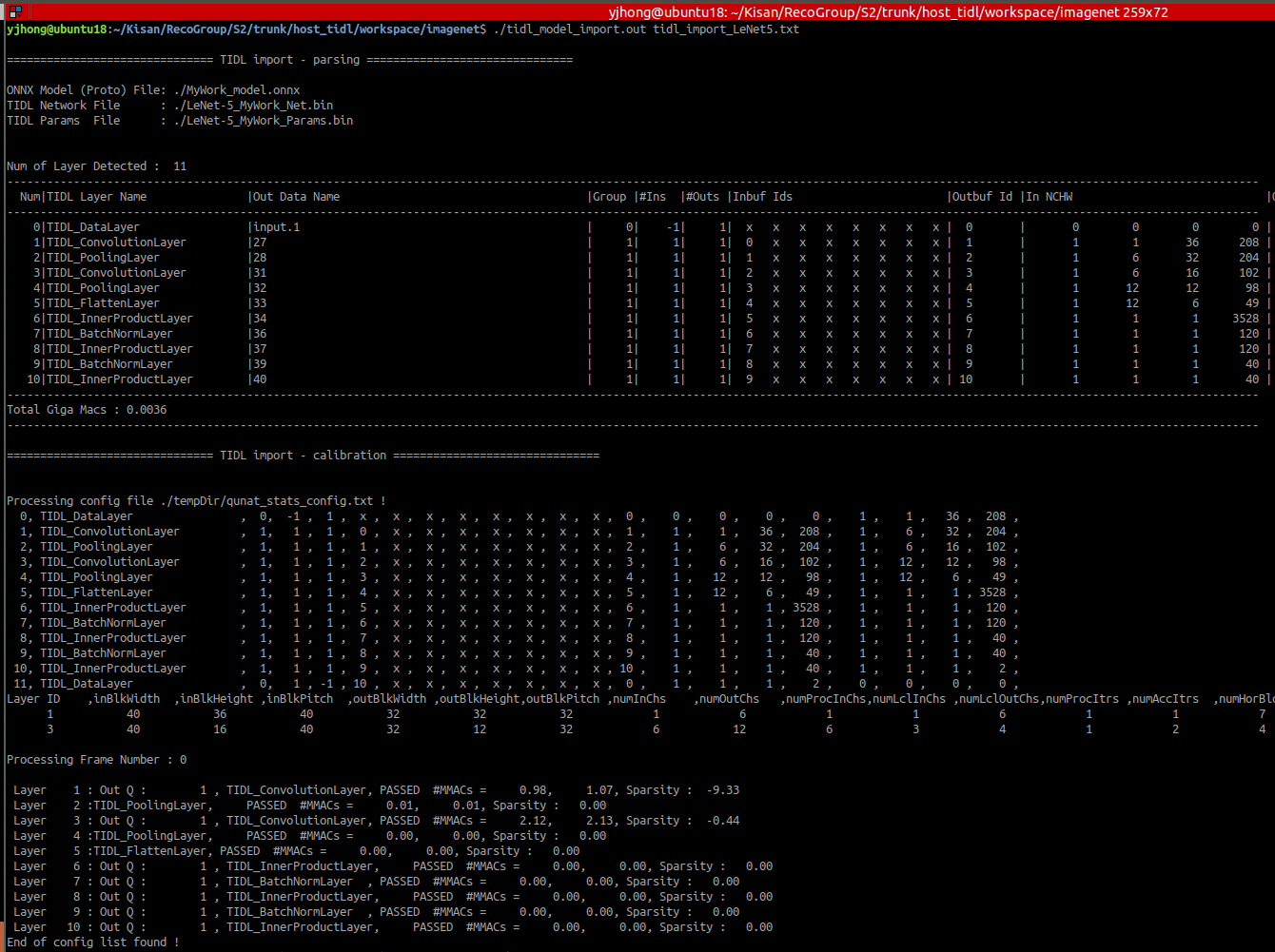
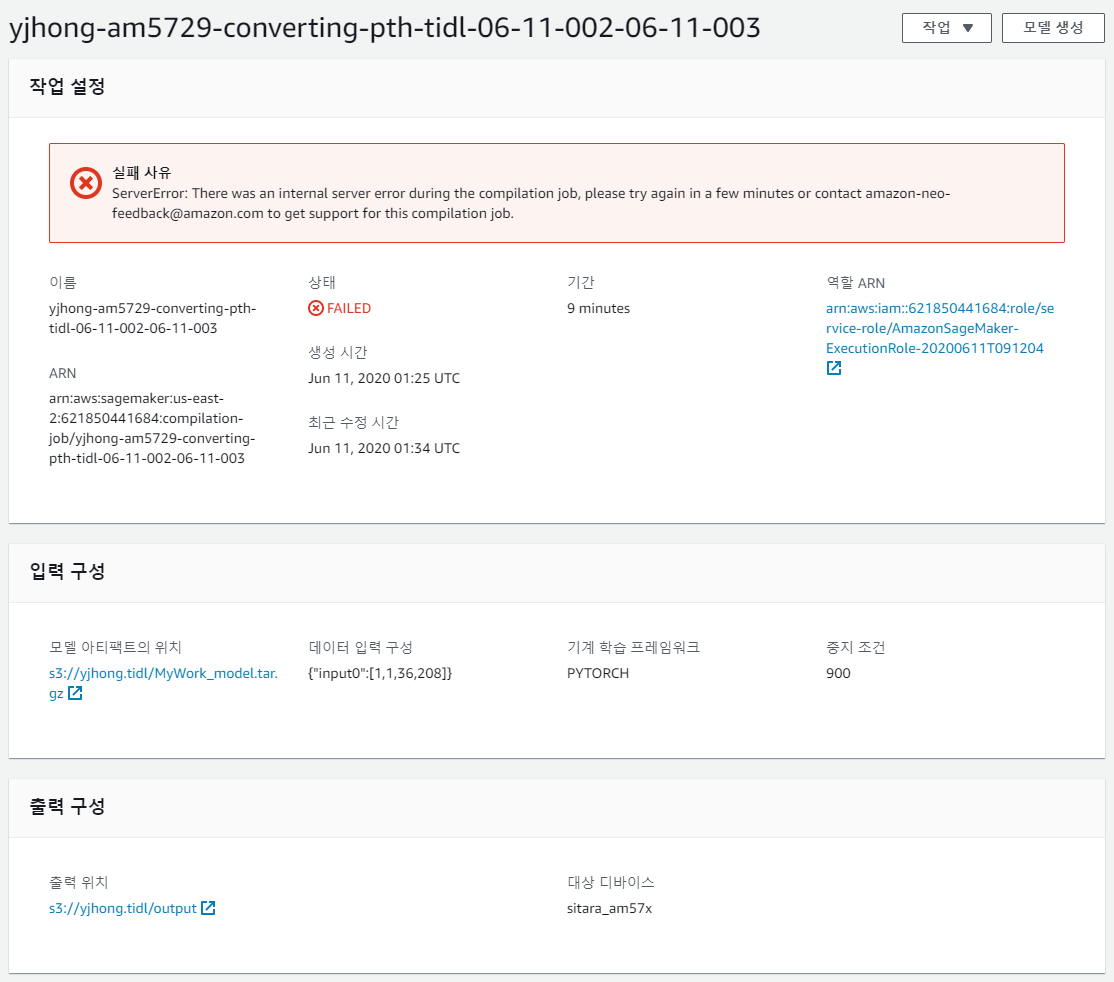
My customer modified imagenet example for CNN binary classification by using Pytorch, and convert it to ONNX(v1.4), and import it to TIDL.
But, the result of TIDL was different from PC's.
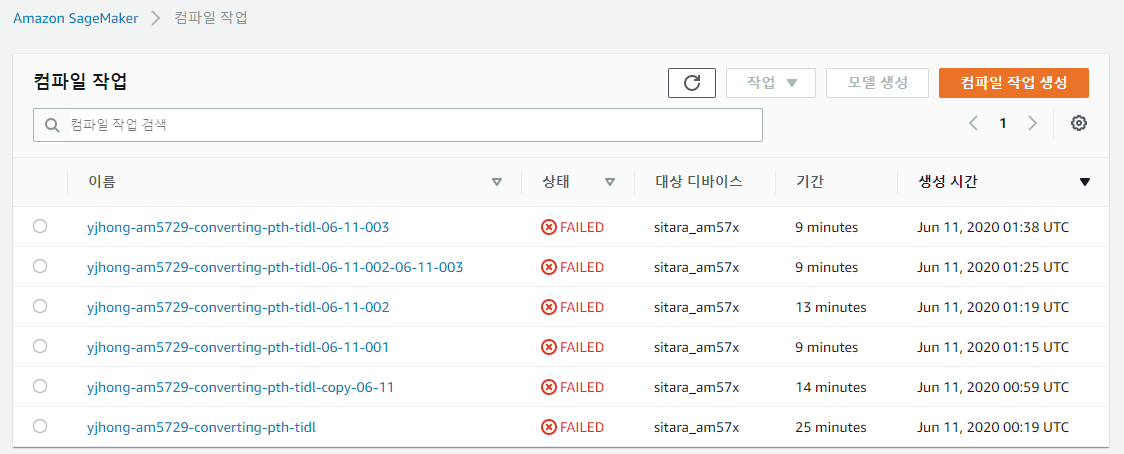
So, I would like to check with you if this work flow is OK or they should use Neo-AI Deep Learning Runtime (DLR).
Could you please help on this?
Thanks and Best Regards,
SI.