Good Morning!
In each of files:
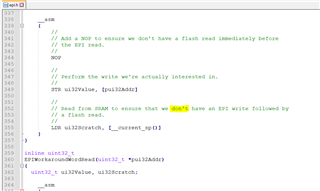
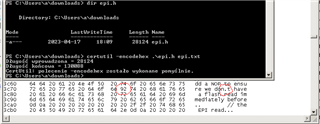
tivaware_c_series_2_1_4_178/driverlib/epi.h
TivaWare_C_Series-2.2.0.295/driverlib/epi.h
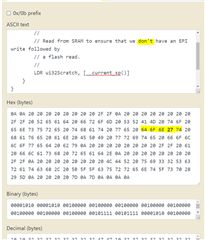
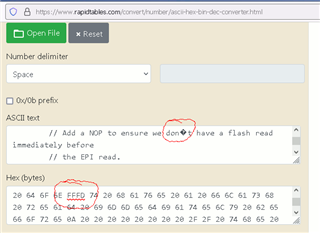
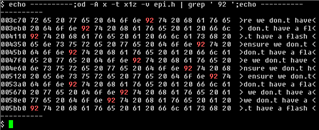
there are 12 places where strange (non-plain-ASCII) 0x92 apostrophe is used in place of plain-ASCII 0x37 code.
I am using Polish letters using UTF-8 and while decoding "epi.h" files I got error in Python 3:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x92 in position 15481: invalid start byte
This error vanishes when plain apostrophe (ASCII hex code 0x37) is used.
Almost all *.c/*.h files in TivaWare use plain 0x37 apostrophe, only "epi.h" (and "tivaware_c_series_2_1_4_178/examples/boards/dk-tm4c129x/ble_central/ble_central.c") use 0x92 code for apostrophe character.

Best wishes,
Piotr Kasprzyk