Part Number: MSP432P4111
Other Parts Discussed in Thread: SYSBIOS
Hi,
I have a problem with SYSBIOS (SimpleLink 3.2) Clock Functions that I hope you can help me debug.
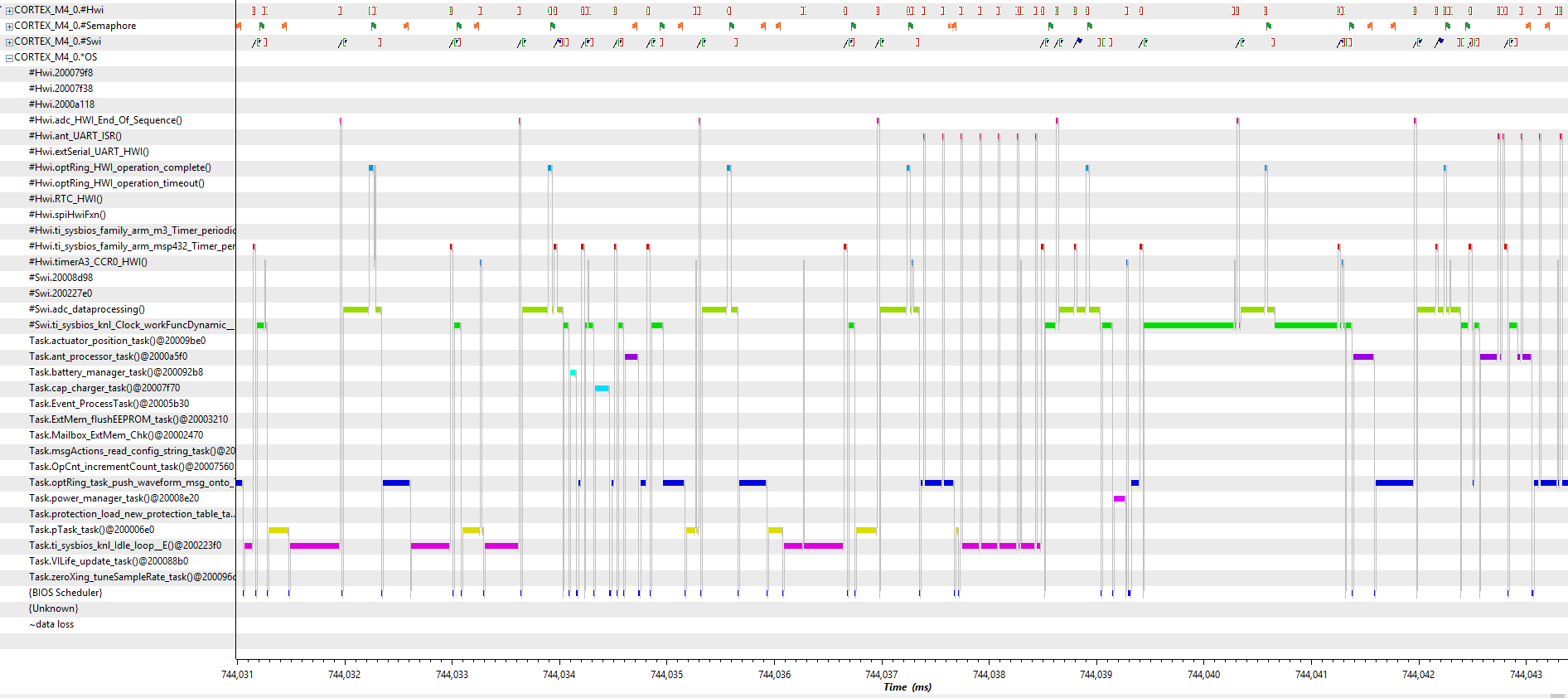
The discussion here is with respect to this Execution Graph, which is typical of our problem. We seem to randomly reach a point where the Clock Function SWI blocks all tasks from running.

On the left of the capture our code is working correctly - a mixture of HWIs, SWIs (including the clock function SWI), Tasks, and a couple of zero latency interrupts (not visible here), are running.
In our system, the clock function SWI runs as the lowest priority SWI, with a tick period of 310uSec [well, given the underlying 32768Hz clock, its actually around 305uSec], unnecessary ticks suppressed. This is a fast tick, but with unnecessary ticks suppressed it doesn't seem to place an unnecessary load on the processor. All our clock functions are dynamically created (i.e. in the code, not in the GUI).
What we are finding is that at some random point in time, the Clock Function SWI starts running all the time, preventing tasks from running, though higher priority SWIs and HWIs continue on. We have not been able to find a reliable trigger - but happens seconds to many minutes after startup.
This transition from normal operation to blocked-by-clock-SWI operation is visible in the execution graph where the cyan traces start becoming very long.
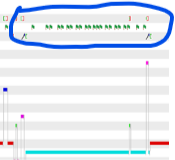
Also notice all the little green flags in the Semaphore row of the execution graph. Each of those flags indicates that one particular Semaphore has been posted. That semaphore is only posted by a clock function (the clock function is a single line of code that posts the semaphore) with a 2mSec period. Here we the semaphore being posted about every 50uSec. This is real - see the CRO trace below.
What this feels like is that all of a sudden the tick for the Clock Function SWI has been reduced from 310uSec to something very small so it monopolizes the processor but I don't see how that can happen.
- The Clock Function uses TimerA0 which is configured to run off ACLK (which runs off LFXT). I've output ACLK to a pin and it looks fine (32.768kHz). Settings for TimerA0 look right.
- There is nothing to indicate there have been any task or HWI stack overflows (per ROV Task and HWI reports)
- Our code does not call Clock_tick() anywhere
- None of our clock functions run for more than maybe 100uSec.
- None of our clock function block - the fact that the semaphore is being repeatedly posted seems to confirm this .
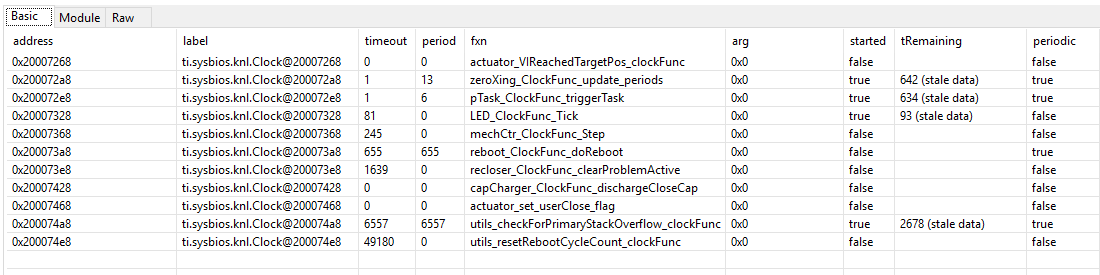
- ROV (see pictures below - I assume ROV retrieves data directly from live SYSBIOS data structures in the micro) seems to indicate Clock tick rate remain at 310uSec, and that clock functions have the right timeouts
- pTask_clockFunc_TriggerTask - this is the clock function that does nothing but set the semaphore. Its timeout of 6 ticks (near enough to 2mSec) is correct.
- zeroXing_ClockFunc_update_periods - this clock function does some background processing roughly every 4 mSec (13 ticks is near enough)
These two screen grabs were takenfrom ROV at the same time as the above Execution graph.

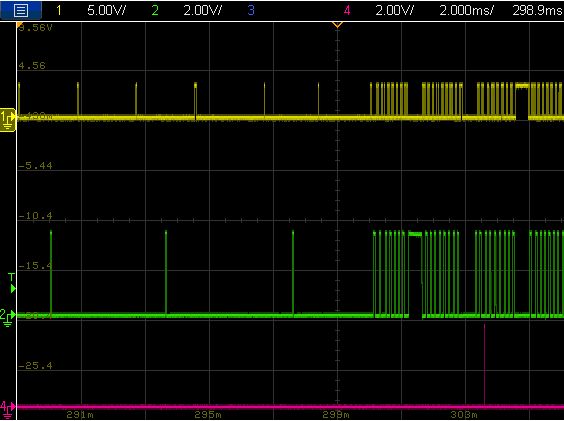
I've setup three of the four active clock functions to set a pin high when they start and go low when they finish. CRO caputure is below. You can clearly see where the clock functions are running at the normal expected cadence and then two of them suddenly start running very quickly.
- Yellow = pTask_ClockFunc_triggerTask
- Green = zeroXing_ClockFunc_update_periods
- Purple = LED_ClockFunc_tick
Just for interest, I let the micro run for a while after it entered this state, then paused execution and looked at ROV again. Here is the clock function information - the tRemaining fields seem to be confused.

Related issues I've found
https://e2e.ti.com/support/legacy_forums/embedded/tirtos/f/355/p/501165/1815469 - I don't think my clock tick is unreasonably slow - particularly with suppress unnecessary ticks enabled. None of my clock functions block.
https://e2e.ti.com/support/legacy_forums/embedded/tirtos/f/355/p/399069/1412086 - All my clock functions run within about 100uSec.
I'd appreciate any help in debugging this issue!
Thank you for your time
Julian