
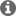


Hello,
As discussed in the related thread, we've been experiencing stalls on the receive path when connecting two PRU-ICSSG ethernet interfaces point to point (E.G. emac0 to emac1).
This has been discussed in a previous thread on this forum: e2e.ti.com/.../am6548-pru-icssg-sr-2-0-receive-stall-with-point-to-point-connection-between-interfaces-on-same-icssg
Luckily, we were able to rule out this type of connection from our use-cases, so this hasn't been a critical issue for us.
Unfortunately, as we've ramped up testing of our custom board, we're seeing several network failures which look very similar to the previous case. One big difference: this happens even when the two PRU-ICSSG ethernet interfaces are not connected point to point. As our technical observations seem to match the ones discussed in the previous thread, I'll state some high-level observations here.
The following setup was used to provoke the issue:
- Our custom board was connected to a host computer. Emac0 and emac1 were connected to two different ethernet interfaces, without any switches/hubs.
The observed issue is as follows:
- After booting the board, the emac interfaces were configured with IP addresses and brought up (I.E. ifconfig emacX <IP address> up).
- When brought into the UP state, both interfaces produces a gratuitous ARP, which were visible on their respective sub-networks (observed via WireShark)
- However, when attempting to ping the board (on both interfaces), only emac0 seems to receive the ping request properly and produce a response.
- When attempting to ping the host computer from the board, network traffic from both emac0 and emac1 was visible - both interfaces made an ARP request towards the host computer
- The host computer responded correctly to both ARP requests
- However, only emac0 seems to receive the ARP response and process it correctly. It then continued to complete a ping request/reply sequence
- emac1 doesn't seem to receive the ARP response at all, and never produces any subsequent ping requests.
The general observation is that the receive path of the secondary interface in an PRU-ICSSG pair (in this case emac1) seems to get stuck in a broken state. This seems to occur as part of system start-up, and we're unable to bring emac1 out of this state. However, the problem doesn't occur every time - in a minority of cases, both interfaces seem to work just fine.
Some additional observations that may or may not be relevant:
- The issue seems less frequent when the operating system/networking drivers are compiled without debugging information - this shouldn't affect the logical path in the driver itself, but it will surely affect timing.
- The issue occurs less frequently when we place a switch between the board and the host computer
- One explanation for this, is that the switch limits the network speed to 100mbps, unlike a point-to-point connection which will auto-negotiate to 1gbps.
- We attempted to restrict the auto-negotiation speed of the network interfaces on the host computer to 100mbps - interestingly, this seems to make things much more stable
- Apart from this, the observations made in the linked forum thread should still be valid and relevant.

