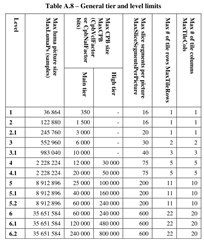
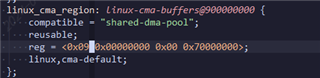
SDK 8.6
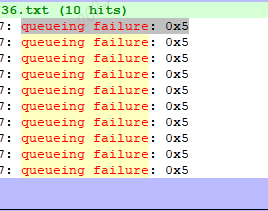
I used an nv12 image with random values for encoding. I found that wave5 will report an error

What does this 0x05 mean?
SDK 8.6
I used an nv12 image with random values for encoding. I found that wave5 will report an error
What does this 0x05 mean?


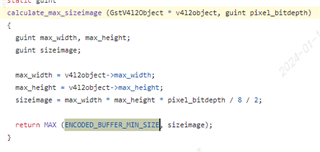

 (gstreamer/subprojects/gst-plugins-good/sys/v4l2/gstv4l2object.c)
(gstreamer/subprojects/gst-plugins-good/sys/v4l2/gstv4l2object.c)