
- Ask a related questionWhat is a related question?A related question is a question created from another question. When the related question is created, it will be automatically linked to the original question.
This thread has been locked.
If you have a related question, please click the "Ask a related question" button in the top right corner. The newly created question will be automatically linked to this question.
Tool/software:
We used the v4l2 framework to capture the image when debugging the ads6311. Found that there will be frame drop. We further analyzed and found that memcpy copy 3932160 bytes, requiring about 30ms. So the dma rate is suspected to be too slow.
ti_csi2rx0: ticsi2rx@30102000 {
compatible = "ti,j721e-csi2rx";
dmas = <&main_bcdma_csi 0 0x5000 15>, <&main_bcdma_csi 0 0x5001 15>,
<&main_bcdma_csi 0 0x5002 15>, <&main_bcdma_csi 0 0x5003 15>;
dma-names = "rx0", "rx1", "rx2", "rx3";
reg = <0x00 0x30102000 0x00 0x1000>;
power-domains = <&k3_pds 182 TI_SCI_PD_EXCLUSIVE>;
#address-cells = <2>;
#size-cells = <2>;
ranges;
status = "disabled";
cdns_csi2rx0: csi-bridge@30101000 {
compatible = "cdns,csi2rx";
reg = <0x00 0x30101000 0x00 0x1000>;
clocks = <&k3_clks 182 0>, <&k3_clks 182 3>, <&k3_clks 182 0>,
<&k3_clks 182 0>, <&k3_clks 182 4>, <&k3_clks 182 4>;
clock-names = "sys_clk", "p_clk", "pixel_if0_clk",
"pixel_if1_clk", "pixel_if2_clk", "pixel_if3_clk";
phys = <&dphy0>;
phy-names = "dphy";
power-domains = <&k3_pds 182 TI_SCI_PD_EXCLUSIVE>;
ports {
#address-cells = <1>;
#size-cells = <0>;
csi0_port0: port@0 {
reg = <0>;
status = "disabled";
};
csi0_port1: port@1 {
reg = <1>;
status = "disabled";
};
csi0_port2: port@2 {
reg = <2>;
status = "disabled";
};
csi0_port3: port@3 {
reg = <3>;
status = "disabled";
};
csi0_port4: port@4 {
reg = <4>;
status = "disabled";
};
};
};
};We changed the priority to 15。
dmas = <&main_bcdma_csi 0 0x5000 15>, <&main_bcdma_csi 0 0x5001 15>,
<&main_bcdma_csi 0 0x5002 15>, <&main_bcdma_csi 0 0x5003 15>;
After the change, we can't capture the data, the data is 0。What method can dma accelerate。
version:09.02.01.10
[2022-04-28 17:44:01 920.392][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 560 us. [2022-04-28 17:44:01 958.194][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 37 ms 115 us. [2022-04-28 17:44:01 959.249][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 510 us. [2022-04-28 17:44:01 994.379][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 35 ms 370 us. [2022-04-28 17:44:02 041.317][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 835 us. [2022-04-28 17:44:02 072.225][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 30 ms 110 us. [2022-04-28 17:44:02 072.900][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 760 us. [2022-04-28 17:44:02 101.438][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 155 us. [2022-04-28 17:44:02 143.028][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 255 us. [2022-04-28 17:44:02 173.251][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 30 ms 825 us. [2022-04-28 17:44:02 174.039][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 320 us. [2022-04-28 17:44:02 202.637][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 715 us. [2022-04-28 17:44:02 245.204][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 335 us. [2022-04-28 17:44:02 275.930][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 30 ms 955 us. [2022-04-28 17:44:02 276.780][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 920 us. [2022-04-28 17:44:02 305.340][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 335 us. [2022-04-28 17:44:02 346.875][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 720 us. [2022-04-28 17:44:02 376.990][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 29 ms 320 us. [2022-04-28 17:44:02 377.672][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 240 us. [2022-04-28 17:44:02 406.416][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 450 us. [2022-04-28 17:44:02 447.903][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 195 us. [2022-04-28 17:44:02 478.259][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 30 ms 15 us. [2022-04-28 17:44:02 478.945][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 925 us. [2022-04-28 17:44:02 507.511][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 345 us. [2022-04-28 17:44:02 549.126][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 955 us. [2022-04-28 17:44:02 578.949][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 29 ms 825 us. [2022-04-28 17:44:02 579.633][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 365 us. [2022-04-28 17:44:02 608.172][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 855 us. [2022-04-28 17:44:02 650.507][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 455 us. [2022-04-28 17:44:02 680.743][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 30 ms 105 us. [2022-04-28 17:44:02 681.429][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 620 us. [2022-04-28 17:44:02 709.895][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 995 us. [2022-04-28 17:44:02 752.961][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 730 us. [2022-04-28 17:44:02 783.158][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 30 ms 600 us. [2022-04-28 17:44:02 783.845][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 885 us. [2022-04-28 17:44:02 812.118][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 25 us. [2022-04-28 17:44:02 854.308][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 625 us. [2022-04-28 17:44:02 885.009][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 30 ms 670 us. [2022-04-28 17:44:02 885.753][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 170 us. [2022-04-28 17:44:02 914.381][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 15 us. [2022-04-28 17:44:02 956.523][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 120 us. [2022-04-28 17:44:02 986.671][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 30 ms 665 us. [2022-04-28 17:44:02 987.366][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 875 us. [2022-04-28 17:44:03 015.852][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 915 us. [2022-04-28 17:44:03 057.990][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 655 us. [2022-04-28 17:44:03 088.190][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 30 ms 925 us. [2022-04-28 17:44:03 088.873][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 805 us. [2022-04-28 17:44:03 117.190][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 800 us. [2022-04-28 17:44:03 159.169][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 115 us. [2022-04-28 17:44:03 189.846][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 30 ms 685 us. [2022-04-28 17:44:03 190.557][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 85 us. [2022-04-28 17:44:03 219.153][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 495 us. [2022-04-28 17:44:03 261.196][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 30 us. [2022-04-28 17:44:03 291.418][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 30 ms 725 us. [2022-04-28 17:44:03 292.128][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 935 us. [2022-04-28 17:44:03 320.719][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 135 us. [2022-04-28 17:44:03 362.983][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 580 us. [2022-04-28 17:44:03 393.157][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 30 ms 880 us. [2022-04-28 17:44:03 393.907][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 935 us. [2022-04-28 17:44:03 422.383][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 0 us. [2022-04-28 17:44:03 518.561][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 15 us. [2022-04-28 17:44:03 609.015][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 35 ms 770 us. [2022-04-28 17:44:03 666.161][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 585 us. [2022-04-28 17:44:03 763.731][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 40 ms 195 us. [2022-04-28 17:44:03 817.190][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 795 us. [2022-04-28 17:44:03 853.640][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 36 ms 885 us. [2022-04-28 17:44:03 855.050][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 380 us. [2022-04-28 17:44:03 886.012][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 30 ms 995 us. [2022-04-28 17:44:03 931.826][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 490 us. [2022-04-28 17:44:03 962.387][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 30 ms 710 us. [2022-04-28 17:44:03 963.150][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 245 us. [2022-04-28 17:44:03 992.393][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 29 ms 490 us. [2022-04-28 17:44:04 034.612][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 395 us. [2022-04-28 17:44:04 064.923][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 30 ms 715 us. [2022-04-28 17:44:04 065.642][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 835 us. [2022-04-28 17:44:04 094.260][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 450 us. [2022-04-28 17:44:04 136.126][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 315 us. [2022-04-28 17:44:04 166.386][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 30 ms 745 us. [2022-04-28 17:44:04 167.078][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 385 us. [2022-04-28 17:44:04 195.572][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 480 us. [2022-04-28 17:44:04 238.629][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 25 us. [2022-04-28 17:44:04 268.790][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 30 ms 805 us. [2022-04-28 17:44:04 269.487][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 40 us. [2022-04-28 17:44:04 297.815][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 350 us. [2022-04-28 17:44:04 338.499][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 665 us. [2022-04-28 17:44:04 368.751][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 30 ms 85 us. [2022-04-28 17:44:04 369.479][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 30 us. [2022-04-28 17:44:04 398.026][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 425 us. [2022-04-28 17:44:04 438.907][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 210 us. [2022-04-28 17:44:04 469.203][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 30 ms 455 us. [2022-04-28 17:44:04 469.950][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 970 us. [2022-04-28 17:44:04 498.897][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 20 us. [2022-04-28 17:44:04 539.838][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 225 us. [2022-04-28 17:44:04 569.548][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 29 ms 925 us. [2022-04-28 17:44:04 570.289][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 70 us. [2022-04-28 17:44:04 598.621][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 165 us. [2022-04-28 17:44:04 639.239][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 245 us. [2022-04-28 17:44:04 669.562][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 30 ms 145 us. [2022-04-28 17:44:04 670.314][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 285 us. [2022-04-28 17:44:04 698.877][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 440 us. [2022-04-28 17:44:04 739.503][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 355 us. [2022-04-28 17:44:04 769.293][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 29 ms 995 us. [2022-04-28 17:44:04 770.067][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 915 us. [2022-04-28 17:44:04 798.622][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 150 us. [2022-04-28 17:44:04 839.169][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 185 us. [2022-04-28 17:44:04 868.976][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 29 ms 570 us. [2022-04-28 17:44:04 869.661][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 930 us. [2022-04-28 17:44:04 898.051][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 545 us. [2022-04-28 17:44:04 938.565][v4l2halapi_cap][callback_process][313]:/dev/video2 copy size 1280 cost: 0 ms 810 us. [2022-04-28 17:44:04 968.780][v4l2halapi_cap][callback_process][313]:/dev/video0 copy size 3932160 cost: 30 ms 180 us. [2022-04-28 17:44:04 969.468][v4l2halapi_cap][callback_process][313]:/dev/video3 copy size 1280 cost: 0 ms 915 us. [2022-04-28 17:44:04 998.033][v4l2halapi_cap][callback_process][313]:/dev/video1 copy size 3932160 cost: 28 ms 565 us.
please help!thank!
[ 0.000000] Booting Linux on physical CPU 0x0000000000 [0x410fd034] [ 0.000000] Linux version 6.6.32 (cd7475193@67f185e364dc) (aarch64-oe-linux-gcc (GCC) 11.4.0, GNU ld (GNU Binutils) 2.38.20220708) #41 SMP PREEMPT Tue Dec 17 07:26:06 UTC 2024 [ 0.000000] KASLR disabled due to lack of seed [ 0.000000] Machine model: Texas Instruments AM62P5 SK [ 0.000000] earlycon: ns16550a0 at MMIO32 0x0000000002800000 (options '') [ 0.000000] printk: bootconsole [ns16550a0] enabled [ 0.000000] efi: UEFI not found. [ 0.000000] [Firmware Bug]: Kernel image misaligned at boot, please fix your bootloader! [ 0.000000] Reserved memory: created CMA memory pool at 0x00000000b0000000, size 144 MiB [ 0.000000] OF: reserved mem: initialized node linux,cma, compatible id shared-dma-pool [ 0.000000] OF: reserved mem: 0x00000000b0000000..0x00000000b8ffffff (147456 KiB) map reusable linux,cma [ 0.000000] Reserved memory: created DMA memory pool at 0x000000009b500000, size 3 MiB [ 0.000000] OF: reserved mem: initialized node rtos-ipc-memory@9b500000, compatible id shared-dma-pool [ 0.000000] OF: reserved mem: 0x000000009b500000..0x000000009b7fffff (3072 KiB) nomap non-reusable rtos-ipc-memory@9b500000 [ 0.000000] Reserved memory: created DMA memory pool at 0x000000009b800000, size 1 MiB [ 0.000000] OF: reserved mem: initialized node mcu-r5fss-dma-memory-region@9b800000, compatible id shared-dma-pool [ 0.000000] OF: reserved mem: 0x000000009b800000..0x000000009b8fffff (1024 KiB) nomap non-reusable mcu-r5fss-dma-memory-region@9b800000 [ 0.000000] Reserved memory: created DMA memory pool at 0x000000009b900000, size 15 MiB [ 0.000000] OF: reserved mem: initialized node mcu-r5fss-memory-region@9b900000, compatible id shared-dma-pool [ 0.000000] OF: reserved mem: 0x000000009b900000..0x000000009c7fffff (15360 KiB) nomap non-reusable mcu-r5fss-memory-region@9b900000 [ 0.000000] Reserved memory: created DMA memory pool at 0x000000009c800000, size 1 MiB [ 0.000000] OF: reserved mem: initialized node r5f-dma-memory@9c800000, compatible id shared-dma-pool [ 0.000000] OF: reserved mem: 0x000000009c800000..0x000000009c8fffff (1024 KiB) nomap non-reusable r5f-dma-memory@9c800000 [ 0.000000] Reserved memory: created DMA memory pool at 0x000000009c900000, size 30 MiB [ 0.000000] OF: reserved mem: initialized node r5f-memory@9c900000, compatible id shared-dma-pool [ 0.000000] OF: reserved mem: 0x000000009c900000..0x000000009e6fffff (30720 KiB) nomap non-reusable r5f-memory@9c900000 [ 0.000000] OF: reserved mem: 0x000000009e780000..0x000000009e7fffff (512 KiB) nomap non-reusable tfa@9e780000 [ 0.000000] OF: reserved mem: 0x000000009e800000..0x000000009fffffff (24576 KiB) nomap non-reusable optee@9e800000 [ 0.000000] Zone ranges: [ 0.000000] DMA [mem 0x0000000080000000-0x00000000bfffffff] [ 0.000000] DMA32 empty [ 0.000000] Normal empty [ 0.000000] Movable zone start for each node [ 0.000000] Early memory node ranges [ 0.000000] node 0: [mem 0x0000000080000000-0x000000009b4fffff] [ 0.000000] node 0: [mem 0x000000009b500000-0x000000009e6fffff] [ 0.000000] node 0: [mem 0x000000009e700000-0x000000009e77ffff] [ 0.000000] node 0: [mem 0x000000009e780000-0x000000009fffffff] [ 0.000000] node 0: [mem 0x00000000a0000000-0x00000000bfffffff] [ 0.000000] Initmem setup node 0 [mem 0x0000000080000000-0x00000000bfffffff] [ 0.000000] psci: probing for conduit method from DT. [ 0.000000] psci: PSCIv1.1 detected in firmware. [ 0.000000] psci: Using standard PSCI v0.2 function IDs [ 0.000000] psci: Trusted OS migration not required [ 0.000000] psci: SMC Calling Convention v1.4 [ 0.000000] percpu: Embedded 20 pages/cpu s42920 r8192 d30808 u81920 [ 0.000000] pcpu-alloc: s42920 r8192 d30808 u81920 alloc=20*4096 [ 0.000000] pcpu-alloc: [0] 0 [0] 1 [0] 2 [0] 3 [ 0.000000] Detected VIPT I-cache on CPU0 [ 0.000000] CPU features: detected: GIC system register CPU interface [ 0.000000] CPU features: detected: ARM erratum 845719 [ 0.000000] alternatives: applying boot alternatives [ 0.000000] Kernel command line: console=ttyS2,115200n8 earlycon=ns16550a,mmio32,0x02800000 root=/dev/mmcblk1p2 rw rootfstype=ext4 rootwait init=/home/root/init-byd.sh loglevel=3 [ 0.000000] Dentry cache hash table entries: 131072 (order: 8, 1048576 bytes, linear) [ 0.000000] Inode-cache hash table entries: 65536 (order: 7, 524288 bytes, linear) [ 0.000000] Built 1 zonelists, mobility grouping on. Total pages: 258048 [ 0.000000] mem auto-init: stack:off, heap alloc:off, heap free:off [ 0.000000] software IO TLB: area num 4. [ 0.000000] software IO TLB: mapped [mem 0x00000000bab80000-0x00000000beb80000] (64MB) [ 0.000000] Memory: 716832K/1048576K available (12416K kernel code, 1284K rwdata, 4256K rodata, 2496K init, 509K bss, 184288K reserved, 147456K cma-reserved) [ 0.000000] SLUB: HWalign=64, Order=0-3, MinObjects=0, CPUs=4, Nodes=1 [ 0.000000] rcu: Preemptible hierarchical RCU implementation. [ 0.000000] rcu: RCU event tracing is enabled. [ 0.000000] rcu: RCU restricting CPUs from NR_CPUS=256 to nr_cpu_ids=4. [ 0.000000] Trampoline variant of Tasks RCU enabled. [ 0.000000] Tracing variant of Tasks RCU enabled. [ 0.000000] rcu: RCU calculated value of scheduler-enlistment delay is 25 jiffies. [ 0.000000] rcu: Adjusting geometry for rcu_fanout_leaf=16, nr_cpu_ids=4 [ 0.000000] NR_IRQS: 64, nr_irqs: 64, preallocated irqs: 0 [ 0.000000] GICv3: GIC: Using split EOI/Deactivate mode [ 0.000000] GICv3: 256 SPIs implemented [ 0.000000] GICv3: 0 Extended SPIs implemented [ 0.000000] Root IRQ handler: gic_handle_irq [ 0.000000] GICv3: GICv3 features: 16 PPIs [ 0.000000] GICv3: CPU0: found redistributor 0 region 0:0x0000000001880000 [ 0.000000] ITS [mem 0x01820000-0x0182ffff] [ 0.000000] GIC: enabling workaround for ITS: Socionext Synquacer pre-ITS [ 0.000000] ITS@0x0000000001820000: Devices Table too large, reduce ids 20->19 [ 0.000000] ITS@0x0000000001820000: allocated 524288 Devices @82400000 (flat, esz 8, psz 64K, shr 0) [ 0.000000] ITS: using cache flushing for cmd queue [ 0.000000] GICv3: using LPI property table @0x0000000081840000 [ 0.000000] GIC: using cache flushing for LPI property table [ 0.000000] GICv3: CPU0: using allocated LPI pending table @0x0000000081850000 [ 0.000000] rcu: srcu_init: Setting srcu_struct sizes based on contention. [ 0.000000] arch_timer: cp15 timer(s) running at 200.00MHz (phys). [ 0.000000] clocksource: arch_sys_counter: mask: 0x3ffffffffffffff max_cycles: 0x2e2049d3e8, max_idle_ns: 440795210634 ns [ 0.000000] sched_clock: 58 bits at 200MHz, resolution 5ns, wraps every 4398046511102ns [ 0.000305] Console: colour dummy device 80x25 [ 0.000351] Calibrating delay loop (skipped), value calculated using timer frequency.. 400.00 BogoMIPS (lpj=800000) [ 0.000362] pid_max: default: 32768 minimum: 301 [ 0.000437] LSM: initializing lsm=capability,integrity [ 0.000525] Mount-cache hash table entries: 2048 (order: 2, 16384 bytes, linear) [ 0.000536] Mountpoint-cache hash table entries: 2048 (order: 2, 16384 bytes, linear) [ 0.002030] RCU Tasks: Setting shift to 2 and lim to 1 rcu_task_cb_adjust=1. [ 0.002090] RCU Tasks Trace: Setting shift to 2 and lim to 1 rcu_task_cb_adjust=1. [ 0.002248] rcu: Hierarchical SRCU implementation. [ 0.002253] rcu: Max phase no-delay instances is 1000. [ 0.002466] Platform MSI: msi-controller@1820000 domain created [ 0.002675] PCI/MSI: /bus@f0000/interrupt-controller@1800000/msi-controller@1820000 domain created [ 0.002900] EFI services will not be available. [ 0.003113] smp: Bringing up secondary CPUs ... [ 0.003728] Detected VIPT I-cache on CPU1 [ 0.003795] GICv3: CPU1: found redistributor 1 region 0:0x00000000018a0000 [ 0.003810] GICv3: CPU1: using allocated LPI pending table @0x0000000081860000 [ 0.003856] CPU1: Booted secondary processor 0x0000000001 [0x410fd034] [ 0.004526] Detected VIPT I-cache on CPU2 [ 0.004579] GICv3: CPU2: found redistributor 2 region 0:0x00000000018c0000 [ 0.004593] GICv3: CPU2: using allocated LPI pending table @0x0000000081870000 [ 0.004624] CPU2: Booted secondary processor 0x0000000002 [0x410fd034] [ 0.005187] Detected VIPT I-cache on CPU3 [ 0.005232] GICv3: CPU3: found redistributor 3 region 0:0x00000000018e0000 [ 0.005243] GICv3: CPU3: using allocated LPI pending table @0x0000000081880000 [ 0.005271] CPU3: Booted secondary processor 0x0000000003 [0x410fd034] [ 0.005330] smp: Brought up 1 node, 4 CPUs [ 0.005344] SMP: Total of 4 processors activated. [ 0.005349] CPU features: detected: 32-bit EL0 Support [ 0.005353] CPU features: detected: CRC32 instructions [ 0.005406] CPU: All CPU(s) started at EL2 [ 0.005409] alternatives: applying system-wide alternatives [ 0.006634] devtmpfs: initialized [ 0.013841] clocksource: jiffies: mask: 0xffffffff max_cycles: 0xffffffff, max_idle_ns: 7645041785100000 ns [ 0.013869] futex hash table entries: 1024 (order: 4, 65536 bytes, linear) [ 0.017652] pinctrl core: initialized pinctrl subsystem [ 0.018080] DMI not present or invalid. [ 0.018635] NET: Registered PF_NETLINK/PF_ROUTE protocol family [ 0.019427] DMA: preallocated 128 KiB GFP_KERNEL pool for atomic allocations [ 0.019504] DMA: preallocated 128 KiB GFP_KERNEL|GFP_DMA pool for atomic allocations [ 0.019576] DMA: preallocated 128 KiB GFP_KERNEL|GFP_DMA32 pool for atomic allocations [ 0.019647] audit: initializing netlink subsys (disabled) [ 0.019822] audit: type=2000 audit(0.016:1): state=initialized audit_enabled=0 res=1 [ 0.020230] thermal_sys: Registered thermal governor 'step_wise' [ 0.020236] thermal_sys: Registered thermal governor 'power_allocator' [ 0.020275] cpuidle: using governor menu [ 0.020465] hw-breakpoint: found 6 breakpoint and 4 watchpoint registers. [ 0.020542] ASID allocator initialised with 65536 entries [ 0.031827] Modules: 27472 pages in range for non-PLT usage [ 0.031842] Modules: 518992 pages in range for PLT usage [ 0.032546] HugeTLB: registered 1.00 GiB page size, pre-allocated 0 pages [ 0.032559] HugeTLB: 0 KiB vmemmap can be freed for a 1.00 GiB page [ 0.032564] HugeTLB: registered 32.0 MiB page size, pre-allocated 0 pages [ 0.032568] HugeTLB: 0 KiB vmemmap can be freed for a 32.0 MiB page [ 0.032573] HugeTLB: registered 2.00 MiB page size, pre-allocated 0 pages [ 0.032576] HugeTLB: 0 KiB vmemmap can be freed for a 2.00 MiB page [ 0.032581] HugeTLB: registered 64.0 KiB page size, pre-allocated 0 pages [ 0.032584] HugeTLB: 0 KiB vmemmap can be freed for a 64.0 KiB page [ 0.033830] k3-chipinfo 43000014.chipid: Family:AM62PX rev:SR1.0 JTAGID[0x0bb9d02f] Detected [ 0.034446] iommu: Default domain type: Translated [ 0.034457] iommu: DMA domain TLB invalidation policy: strict mode [ 0.034707] SCSI subsystem initialized [ 0.034849] libata version 3.00 loaded. [ 0.035016] usbcore: registered new interface driver usbfs [ 0.035047] usbcore: registered new interface driver hub [ 0.035073] usbcore: registered new device driver usb [ 0.035426] mc: Linux media interface: v0.10 [ 0.035459] videodev: Linux video capture interface: v2.00 [ 0.035489] pps_core: LinuxPPS API ver. 1 registered [ 0.035493] pps_core: Software ver. 5.3.6 - Copyright 2005-2007 Rodolfo Giometti <giometti@linux.it> [ 0.035505] PTP clock support registered [ 0.035636] EDAC MC: Ver: 3.0.0 [ 0.036032] scmi_core: SCMI protocol bus registered [ 0.036277] FPGA manager framework [ 0.036357] Advanced Linux Sound Architecture Driver Initialized. [ 0.037158] vgaarb: loaded [ 0.037476] clocksource: Switched to clocksource arch_sys_counter [ 0.037682] VFS: Disk quotas dquot_6.6.0 [ 0.037708] VFS: Dquot-cache hash table entries: 512 (order 0, 4096 bytes) [ 0.042884] NET: Registered PF_INET protocol family [ 0.043016] IP idents hash table entries: 16384 (order: 5, 131072 bytes, linear) [ 0.043856] tcp_listen_portaddr_hash hash table entries: 512 (order: 1, 8192 bytes, linear) [ 0.043878] Table-perturb hash table entries: 65536 (order: 6, 262144 bytes, linear) [ 0.043889] TCP established hash table entries: 8192 (order: 4, 65536 bytes, linear) [ 0.043976] TCP bind hash table entries: 8192 (order: 6, 262144 bytes, linear) [ 0.044176] TCP: Hash tables configured (established 8192 bind 8192) [ 0.044274] UDP hash table entries: 512 (order: 2, 16384 bytes, linear) [ 0.044302] UDP-Lite hash table entries: 512 (order: 2, 16384 bytes, linear) [ 0.044443] NET: Registered PF_UNIX/PF_LOCAL protocol family [ 0.044810] RPC: Registered named UNIX socket transport module. [ 0.044818] RPC: Registered udp transport module. [ 0.044822] RPC: Registered tcp transport module. [ 0.044825] RPC: Registered tcp-with-tls transport module. [ 0.044829] RPC: Registered tcp NFSv4.1 backchannel transport module. [ 0.044836] NET: Registered PF_XDP protocol family [ 0.044854] PCI: CLS 0 bytes, default 64 [ 0.046019] Initialise system trusted keyrings [ 0.046212] workingset: timestamp_bits=46 max_order=18 bucket_order=0 [ 0.046489] squashfs: version 4.0 (2009/01/31) Phillip Lougher [ 0.046700] NFS: Registering the id_resolver key type [ 0.046727] Key type id_resolver registered [ 0.046731] Key type id_legacy registered [ 0.046749] nfs4filelayout_init: NFSv4 File Layout Driver Registering... [ 0.046754] nfs4flexfilelayout_init: NFSv4 Flexfile Layout Driver Registering... [ 0.073806] Key type asymmetric registered [ 0.073816] Asymmetric key parser 'x509' registered [ 0.073865] Block layer SCSI generic (bsg) driver version 0.4 loaded (major 241) [ 0.073872] io scheduler mq-deadline registered [ 0.073877] io scheduler kyber registered [ 0.073906] io scheduler bfq registered [ 0.076551] pinctrl-single 4084000.pinctrl: 34 pins, size 136 [ 0.077105] pinctrl-single f4000.pinctrl: 171 pins, size 684 [ 0.082934] Serial: 8250/16550 driver, 12 ports, IRQ sharing enabled [ 0.091550] loop: module loaded [ 0.092429] megasas: 07.725.01.00-rc1 [ 0.095660] tun: Universal TUN/TAP device driver, 1.6 [ 0.096509] VFIO - User Level meta-driver version: 0.3 [ 0.097434] usbcore: registered new interface driver usb-storage [ 0.097967] i2c_dev: i2c /dev entries driver [ 0.099411] sdhci: Secure Digital Host Controller Interface driver [ 0.099421] sdhci: Copyright(c) Pierre Ossman [ 0.099604] sdhci-pltfm: SDHCI platform and OF driver helper [ 0.100233] ledtrig-cpu: registered to indicate activity on CPUs [ 0.100493] SMCCC: SOC_ID: ARCH_SOC_ID not implemented, skipping .... [ 0.101070] usbcore: registered new interface driver usbhid [ 0.101075] usbhid: USB HID core driver [ 0.101333] omap-mailbox 29000000.mailbox: omap mailbox rev 0x66fca100 [ 0.101459] omap-mailbox 29010000.mailbox: omap mailbox rev 0x66fca100 [ 0.101559] omap-mailbox 29020000.mailbox: no available mbox devices found [ 0.101595] omap-mailbox 29030000.mailbox: no available mbox devices found [ 0.103039] hw perfevents: enabled with armv8_cortex_a53 PMU driver, 7 counters available [ 0.103537] optee: probing for conduit method. [ 0.103563] optee: revision 4.2 (12d7c4ee) [ 0.103835] optee: dynamic shared memory is enabled [ 0.104040] optee: initialized driver [ 0.105369] NET: Registered PF_PACKET protocol family [ 0.105444] Key type dns_resolver registered [ 0.112921] registered taskstats version 1 [ 0.113103] Loading compiled-in X.509 certificates [ 0.124033] ti-sci 44043000.system-controller: ABI: 4.0 (firmware rev 0x000a '10.0.8--v10.00.08 (Fiery Fox)') [ 0.167391] platform 79000000.r5f: R5F core may have been powered on by a different host, programmed state (0) != actual state (1) [ 0.167553] platform 79000000.r5f: configured R5F for IPC-only mode [ 0.167643] platform 79000000.r5f: assigned reserved memory node mcu-r5fss-dma-memory-region@9b800000 [ 0.168040] remoteproc remoteproc0: 79000000.r5f is available [ 0.168094] remoteproc remoteproc0: attaching to 79000000.r5f [ 0.168547] platform 79000000.r5f: R5F core initialized in IPC-only mode [ 0.168568] rproc-virtio rproc-virtio.0.auto: assigned reserved memory node mcu-r5fss-dma-memory-region@9b800000 [ 0.169095] virtio_rpmsg_bus virtio0: rpmsg host is online [ 0.169116] rproc-virtio rproc-virtio.0.auto: registered virtio0 (type 7) [ 0.169124] remoteproc remoteproc0: remote processor 79000000.r5f is now attached [ 0.169391] virtio_rpmsg_bus virtio0: creating channel ti.ipc4.ping-pong addr 0xd [ 0.169494] virtio_rpmsg_bus virtio0: creating channel rpmsg_chrdev addr 0xe [ 0.170095] ti-sci-intr bus@f0000:interrupt-controller@a00000: Interrupt Router 3 domain created [ 0.170361] ti-sci-inta 48000000.interrupt-controller: Interrupt Aggregator domain 28 created [ 0.170702] ti-sci-inta 4e400000.interrupt-controller: Interrupt Aggregator domain 200 created [ 0.171921] ti-udma 485c0100.dma-controller: Number of rings: 82 [ 0.174170] ti-udma 485c0100.dma-controller: Channels: 48 (bchan: 18, tchan: 12, rchan: 18) [ 0.176349] ti-udma 485c0000.dma-controller: Number of rings: 150 [ 0.180762] ti-udma 485c0000.dma-controller: Channels: 35 (tchan: 20, rchan: 15) [ 0.182501] ti-udma 4e230000.dma-controller: Number of rings: 6 [ 0.183011] ti-udma 4e230000.dma-controller: Channels: 6 (bchan: 0, tchan: 0, rchan: 6) [ 0.184157] printk: console [ttyS2] disabled [ 0.184449] 2800000.serial: ttyS2 at MMIO 0x2800000 (irq = 249, base_baud = 3000000) is a 8250 [ 0.184515] printk: console [ttyS2] enabled [ 0.184520] printk: bootconsole [ns16550a0] disabled [ 0.187883] spi spi1.0: Fixed dependency cycle(s) with /bus@f0000/ticsi2rx@30102000/csi-bridge@30101000 [ 0.225483] davinci_mdio 8000f00.mdio: davinci mdio revision 17.7, bus freq 1000000 [ 0.225731] mdio_bus 8000f00.mdio: MDIO device at address 0 is missing. [ 0.225953] mdio_bus 8000f00.mdio: MDIO device at address 1 is missing. [ 0.226005] am65-cpsw-nuss 8000000.ethernet: initializing am65 cpsw nuss version 0x6BA01903, cpsw version 0x6BA81903 Ports: 3 quirks:00000006 [ 0.226373] am65-cpsw-nuss 8000000.ethernet: Use random MAC address [ 0.226386] am65-cpsw-nuss 8000000.ethernet: initialized cpsw ale version 1.5 [ 0.226392] am65-cpsw-nuss 8000000.ethernet: ALE Table size 512 [ 0.227020] am65-cpsw-nuss 8000000.ethernet: CPTS ver 0x4e8a010d, freq:500000000, add_val:1 pps:0 [ 0.231961] am65-cpsw-nuss 8000000.ethernet: set new flow-id-base 19 [ 0.239460] xhci-hcd xhci-hcd.1.auto: xHCI Host Controller [ 0.239491] xhci-hcd xhci-hcd.1.auto: new USB bus registered, assigned bus number 1 [ 0.239655] xhci-hcd xhci-hcd.1.auto: USB3 root hub has no ports [ 0.239663] xhci-hcd xhci-hcd.1.auto: hcc params 0x0258fe6d hci version 0x110 quirks 0x0000008020000010 [ 0.239716] xhci-hcd xhci-hcd.1.auto: irq 264, io mem 0x31100000 [ 0.240493] hub 1-0:1.0: USB hub found [ 0.240528] hub 1-0:1.0: 1 port detected [ 0.246670] spi spi1.0: Fixed dependency cycle(s) with /bus@f0000/ticsi2rx@30102000/csi-bridge@30101000 [ 0.246746] platform 30101000.csi-bridge: Fixed dependency cycle(s) with /bus@f0000/spi@20110000/ads6311_spi@0 [ 0.247463] cdns-csi2rx 30101000.csi-bridge: Probed CSI2RX with 4/4 lanes, 4 streams, external D-PHY [ 0.250218] mmc0: CQHCI version 5.10 [ 0.250626] mmc1: CQHCI version 5.10 [ 0.258131] debugfs: Directory 'pd:244' with parent 'pm_genpd' already present! [ 0.258174] debugfs: Directory 'pd:244' with parent 'pm_genpd' already present! [ 0.258182] debugfs: Directory 'pd:243' with parent 'pm_genpd' already present! [ 0.258188] debugfs: Directory 'pd:186' with parent 'pm_genpd' already present! [ 0.259458] debugfs: Directory 'pd:182' with parent 'pm_genpd' already present! [ 0.259472] debugfs: Directory 'pd:182' with parent 'pm_genpd' already present! [ 0.260516] ----- Probe Start ---driver_version: 3.2.0_LM20240904a---- [ 0.286023] mmc0: SDHCI controller on fa10000.mmc [fa10000.mmc] using ADMA 64-bit [ 0.294025] mmc1: SDHCI controller on fa00000.mmc [fa00000.mmc] using ADMA 64-bit [ 0.297503] ads6311 virtio0.ti.ipc4.ping-pong.-1.13: mcuctrl_rpmsg_probe() Line:9458 [ 0.297516] new channel: 0x401 -> 0xd, rpmsg_device_id: ti.ipc4.ping-pong, endpoint address: 0x401! [ 0.329091] mmc1: new high speed SDXC card at address aaaa [ 0.329707] mmcblk1: mmc1:aaaa SD64G 59.5 GiB [ 0.331684] mmcblk1: p1 p2 p3 [ 0.401490] rpmsg wait for completion time-out [ 0.401501] rpmsg read reg:0x0000 failed, ret:-110, rpmsg_from_user: 0 [ 0.401509] read mcuctrl reg[0x0000] return data:0x0000, ret:-110 [ 0.456982] mmc0: Command Queue Engine enabled [ 0.457002] mmc0: new HS400 MMC card at address 0001 [ 0.457596] mmcblk0: mmc0:0001 8GUF4R 7.28 GiB [ 0.460021] mmcblk0: p1 p2 p3 p4 p5 [ 0.460792] mmcblk0boot0: mmc0:0001 8GUF4R 31.9 MiB [ 0.461603] mmcblk0boot1: mmc0:0001 8GUF4R 31.9 MiB [ 0.462366] mmcblk0rpmb: mmc0:0001 8GUF4R 4.00 MiB, chardev (236:0) [ 0.505488] rpmsg wait for completion time-out [ 0.505498] rpmsg read reg:0x0020 failed, ret:-110, rpmsg_from_user: 0 [ 0.505507] Fail to read mcu firmware type, ret:-110 [ 0.609479] rpmsg wait for completion time-out [ 0.609482] rpmsg read reg:0x0010 failed, ret:-110, rpmsg_from_user: 0 [ 0.609487] Fail to read mcu firmware version, ret:-110 [ 0.713478] rpmsg wait for completion time-out for 100 ms. [ 0.713485] rpmsg_tx: 00000000: 00 03 00 81 f6 3c 47 .....<G [ 0.713492] rpmsg Write mcu reg:0x0081 failed, ret:-110, rpmsg_from_user: 0 [ 0.713497] done, ret:0! [ 0.713564] SPI driver adaps,ads6311spi has no spi_device_id for adaps,ads6311spi [ 0.713641] adaps,ads6311spi spi1.0: cam_sensor_spi_driver_probe() Line:7903 <DRV_ADS6311> spi_controller : spi1 (____ptrval____) name=ads6311spi,bus_num=1,irq:0 mode:0x0 spi max_speed:15000000 [ 0.713656] name=ads6311spi,bus_num=1,irq[0] cs[0] mode[0] CPHA[0] CPOL[0] CS_HIGH[0] msb_first[1] the original spi max_speed[15000000] [ 0.713665] ------TRACE_PM_RUNTIME--Begin of <__sensor_power_on> Line:4003--power_on:0, callline: 7489, sensor->power_on_times: 0--- [ 0.817484] rpmsg wait for completion time-out for 100 ms. [ 0.817494] rpmsg_tx: 00000000: 00 04 00 bd 00 01 b7 ....... [ 0.817499] rpmsg Write mcu reg:0x00bd failed, ret:-110, rpmsg_from_user: 0 [ 0.817504] Fail to power on tx and rx modules. [ 0.817507] Failed to power on tx and rx modules. [ 0.921478] rpmsg wait for completion time-out for 100 ms. [ 0.921483] rpmsg_tx: 00000000: 00 05 00 8a 00 00 80 ....... [ 0.921488] rpmsg Write mcu reg:0x008a failed, ret:-110, rpmsg_from_user: 0 [ 0.921492] Fail to set rx work mode: 0. [ 0.924038] Success for sensor reset cost 2541 us, sensor chip id: 0x3400 [ 0.924195] ------TRACE_PM_RUNTIME--End of <__sensor_power_on> Line:4167--power_on:1, load_script: 0, ret: 0, sensorId: 0x3400--- [ 0.924258] client: swapper/0 (1:1) is running on CPU 2 [ 0.925397] done, ret:0! [ 0.925708] clk: Disabling unused clocks [ 0.932236] ALSA device list: [ 0.932248] No soundcards found. [ 0.974933] EXT4-fs (mmcblk1p2): recovery complete [ 0.975834] EXT4-fs (mmcblk1p2): mounted filesystem 2335e32d-28f4-4616-95c9-cdb7a9c8e61a r/w with ordered data mode. Quota mode: none. [ 0.975900] VFS: Mounted root (ext4 filesystem) on device 179:2. [ 0.983494] devtmpfs: mounted [ 0.984218] Freeing unused kernel memory: 2496K [ 0.984325] Run /home/root/init-byd.sh as init process [ 0.984331] with arguments: [ 0.984333] /home/root/init-byd.sh [ 0.984336] with environment: [ 0.984339] HOME=/ [ 0.984341] TERM=linux [ 1.686376] systemd[1]: System time before build time, advancing clock. [ 1.733537] systemd[1]: systemd 255.4^ running in system mode (+PAM -AUDIT -SELINUX -APPARMOR +IMA -SMACK +SECCOMP -GCRYPT -GNUTLS -OPENSSL +ACL +BLKID -CURL -ELFUTILS -FIDO2 -IDN2 -IDN -IPTC +KMOD -LIBCRYPTSETUP +LIBFDISK -PCRE2 -PWQUALITY -P11KIT -QRENCODE -TPM2 -BZIP2 -LZ4 -XZ -ZLIB +ZSTD -BPF_FRAMEWORK -XKBCOMMON +UTMP +SYSVINIT default-hierarchy=unified) [ 1.733572] systemd[1]: Detected architecture arm64. [ 1.748695] systemd[1]: Hostname set to <am62pxx-evm>. [ 1.985024] systemd[1]: Configuration file /usr/lib/systemd/system/ti-apps-launcher.service is marked executable. Please remove executable permission bits. Proceeding anyway. [ 1.987440] systemd[1]: Configuration file /usr/lib/systemd/system/seva-launcher.service is marked executable. Please remove executable permission bits. Proceeding anyway. [ 2.041537] systemd[1]: Binding to IPv6 address not available since kernel does not support IPv6. [ 2.041582] systemd[1]: Binding to IPv6 address not available since kernel does not support IPv6. [ 2.080933] systemd[1]: /usr/lib/systemd/system/bt-enable.service:9: Standard output type syslog is obsolete, automatically updating to journal. Please update your unit file, and consider removing the setting altogether. [ 2.177658] systemd[1]: /etc/systemd/system/sync-clocks.service:11: Standard output type syslog is obsolete, automatically updating to journal. Please update your unit file, and consider removing the setting altogether. [ 2.248943] systemd[1]: Queued start job for default target Graphical Interface. [ 2.274709] systemd[1]: Created slice Slice /system/getty. [ 2.277094] systemd[1]: Created slice Slice /system/modprobe. [ 2.279283] systemd[1]: Created slice Slice /system/serial-getty. [ 2.280926] systemd[1]: Created slice User and Session Slice. [ 2.281381] systemd[1]: Started Dispatch Password Requests to Console Directory Watch. [ 2.281735] systemd[1]: Started Forward Password Requests to Wall Directory Watch. [ 2.281905] systemd[1]: Expecting device /dev/ttyS2... [ 2.282101] systemd[1]: Reached target Path Units. [ 2.282215] systemd[1]: Reached target Remote File Systems. [ 2.282324] systemd[1]: Reached target Slice Units. [ 2.282428] systemd[1]: Reached target Swaps. [ 2.292027] systemd[1]: Listening on RPCbind Server Activation Socket. [ 2.292368] systemd[1]: Reached target RPC Port Mapper. [ 2.299513] systemd[1]: Listening on Process Core Dump Socket. [ 2.300027] systemd[1]: Listening on initctl Compatibility Named Pipe. [ 2.301149] systemd[1]: Listening on Journal Audit Socket. [ 2.301938] systemd[1]: Listening on Journal Socket (/dev/log). [ 2.302644] systemd[1]: Listening on Journal Socket. [ 2.303481] systemd[1]: Listening on Network Service Netlink Socket. [ 2.304268] systemd[1]: Listening on udev Control Socket. [ 2.304802] systemd[1]: Listening on udev Kernel Socket. [ 2.305330] systemd[1]: Listening on User Database Manager Socket. [ 2.311157] systemd[1]: Mounting Huge Pages File System... [ 2.315177] systemd[1]: Mounting POSIX Message Queue File System... [ 2.320561] systemd[1]: Mounting Kernel Debug File System... [ 2.321340] systemd[1]: Kernel Trace File System was skipped because of an unmet condition check (ConditionPathExists=/sys/kernel/tracing). [ 2.334183] systemd[1]: Mounting Temporary Directory /tmp... [ 2.334936] systemd[1]: Create List of Static Device Nodes was skipped because of an unmet condition check (ConditionFileNotEmpty=/lib/modules/6.6.32/modules.devname). [ 2.342359] systemd[1]: Starting Load Kernel Module configfs... [ 2.350466] systemd[1]: Starting Load Kernel Module drm... [ 2.358454] systemd[1]: Starting Load Kernel Module fuse... [ 2.370441] systemd[1]: Starting Start psplash boot splash screen... [ 2.380873] systemd[1]: Starting RPC Bind... [ 2.381369] systemd[1]: File System Check on Root Device was skipped because of an unmet condition check (ConditionPathIsReadWrite=!/). [ 2.390804] systemd[1]: Starting Journal Service... [ 2.401421] systemd[1]: Starting Load Kernel Modules... [ 2.407443] systemd[1]: Starting Generate network units from Kernel command line... [ 2.418535] systemd[1]: Starting Remount Root and Kernel File Systems... [ 2.436593] systemd[1]: Starting Create Static Device Nodes in /dev gracefully... [ 2.443687] systemd[1]: Starting Coldplug All udev Devices... [ 2.449727] systemd[1]: Bind mount volatile /var/cache was skipped because of an unmet condition check (ConditionPathIsReadWrite=!/var/cache). [ 2.450115] systemd[1]: Bind mount volatile /var/lib was skipped because of an unmet condition check (ConditionPathIsReadWrite=!/var/lib). [ 2.450415] systemd[1]: Bind mount volatile /var/spool was skipped because of an unmet condition check (ConditionPathIsReadWrite=!/var/spool). [ 2.450699] systemd[1]: Bind mount volatile /srv was skipped because of an unmet condition check (ConditionPathIsReadWrite=!/srv). [ 2.459649] systemd[1]: Mounted Huge Pages File System. [ 2.460933] systemd[1]: Mounted POSIX Message Queue File System. [ 2.462156] systemd[1]: Mounted Kernel Debug File System. [ 2.463134] systemd[1]: Mounted Temporary Directory /tmp. [ 2.464783] systemd[1]: modprobe@configfs.service: Deactivated successfully. [ 2.465708] systemd[1]: Finished Load Kernel Module configfs. [ 2.467292] systemd[1]: modprobe@drm.service: Deactivated successfully. [ 2.468073] systemd[1]: Finished Load Kernel Module drm. [ 2.469695] systemd[1]: modprobe@fuse.service: Deactivated successfully. [ 2.470650] systemd[1]: Finished Load Kernel Module fuse. [ 2.471932] systemd[1]: psplash-start.service: Main process exited, code=exited, status=255/EXCEPTION [ 2.472919] systemd[1]: psplash-start.service: Failed with result 'exit-code'. [ 2.474340] systemd[1]: Failed to start Start psplash boot splash screen. [ 2.474726] systemd[1]: Dependency failed for Start psplash-systemd progress communication helper. [ 2.474899] systemd[1]: psplash-systemd.service: Job psplash-systemd.service/start failed with result 'dependency'. [ 2.477008] systemd[1]: FUSE Control File System was skipped because of an unmet condition check (ConditionPathExists=/sys/fs/fuse/connections). [ 2.482350] systemd[1]: Mounting Kernel Configuration File System... [ 2.484430] systemd[1]: Finished Load Kernel Modules. [ 2.507380] systemd[1]: Starting Apply Kernel Variables... [ 2.529654] systemd[1]: Finished Generate network units from Kernel command line. [ 2.530520] systemd[1]: Started RPC Bind. [ 2.531338] systemd[1]: Mounted Kernel Configuration File System. [ 2.545878] systemd-journald[130]: Collecting audit messages is enabled. [ 2.553770] EXT4-fs (mmcblk1p2): re-mounted 2335e32d-28f4-4616-95c9-cdb7a9c8e61a r/w. Quota mode: none. [ 2.558379] systemd[1]: Finished Remount Root and Kernel File Systems. [ 2.562636] systemd[1]: Rebuild Hardware Database was skipped because of an unmet condition check (ConditionNeedsUpdate=/etc). [ 2.590319] systemd[1]: Starting Load/Save OS Random Seed... [ 2.592059] systemd[1]: Finished Create Static Device Nodes in /dev gracefully. [ 2.593586] systemd[1]: Finished Apply Kernel Variables. [ 2.594642] systemd[1]: Create System Users was skipped because no trigger condition checks were met. [ 2.602368] systemd[1]: Starting Create Static Device Nodes in /dev... [ 2.625733] systemd[1]: Started Journal Service. [ 2.692806] systemd-journald[130]: Received client request to flush runtime journal. [ 3.529560] random: crng init done [ 4.368908] client: v4l_id (392:392) is running on CPU 1 [ 4.368951] ---- S_OPEN from v4l_id (392:392) on CPU 1 [ 4.368997] ---- S_CLOSE from v4l_id (392:392) on CPU 1 [ 7.347380] EXT4-fs (mmcblk0p3): mounted filesystem e6a33725-a377-4170-9a67-9234ff837bd1 r/w with ordered data mode. Quota mode: none. [ 7.463185] EXT4-fs (mmcblk0p4): mounted filesystem c5eb58d1-5689-456e-be20-720870df908b r/w with ordered data mode. Quota mode: none. [ 7.505741] EXT4-fs (mmcblk0p2): mounted filesystem e6a33725-a377-4170-9a67-9234ff837bd1 r/w with ordered data mode. Quota mode: none. [ 7.519601] EXT4-fs (mmcblk0p5): mounted filesystem 633c4968-c00f-4d05-b385-f93b1b41464d r/w with ordered data mode. Quota mode: none. [ 8.476504] EXT4-fs (mmcblk1p3): mounted filesystem 17d20f3a-a58b-43de-a118-a560fbebc0bd r/w with ordered data mode. Quota mode: none. [ 48.723704] client: media-ctl (949:949) is running on CPU 2, pad: 0, name:m00_dToF_ads6311 spi1.0, fd: 00000000a3aa9c0d [ 48.723730] num_routes: 4, source_pad: 0, source_stream: 0 [ 48.723736] num_entries: 0, w*h: 480 * 128, code: 0x3008, bpp: 16 [ 48.723742] num_routes: 4, source_pad: 0, source_stream: 1 [ 48.723746] num_entries: 1, w*h: 480 * 128, code: 0x3008, bpp: 16 [ 48.723751] num_routes: 4, source_pad: 0, source_stream: 2 [ 48.723756] num_entries: 2, w*h: 40 * 1, code: 0x3001, bpp: 8 [ 48.723761] num_routes: 4, source_pad: 0, source_stream: 3 [ 48.723765] num_entries: 3, w*h: 40 * 1, code: 0x3001, bpp: 8 [ 54.660005] client: hawk_concurrenc (951:951) is running on CPU 2 [ 54.660043] ---- S_OPEN from hawk_concurrenc (951:951) on CPU 2 [ 54.660064] ---- M_OPEN from hawk_concurrenc (951:951) on CPU 2 [ 54.660070] sensor->mmap_buffer_base: 00000000549e9bba, 0xffff000003900000 [ 54.660076] client: hawk_concurrenc (951) [ 54.660080] code section: [0x400000 0x418e24] [ 54.660085] data section: [0x429d88 0x42a2f0] [ 54.660088] brk section: s: 0x2979d000, c: 0x297be000 [ 54.660092] mmap section: s: 0xffffa2520000 [ 54.660095] stack section: s: 0xffffde104260 [ 54.660098] arg section: [0xffffde104db7 0xffffde104dee] [ 54.660102] env section: [0xffffde104dee 0xffffde104fe0] [ 54.660144] client: hawk_concurrenc (951:951) subframe_count: 32, load_script: 0, streaming: 0, pad: 0, stream: 0, code: 0x0, state: 000000007006af02, which:0x1, width:32, height:192 [ 54.660164] fmt->which: 1, pad: 0, stream: 0, code: 0x3008, w*h: 32*192. [ 55.666175] client: hawk_concurrenc (951:951) is running on CPU 2, pad: 0, name:m00_dToF_ads6311 spi1.0, fd: 000000003963de67 [ 55.666200] num_routes: 4, source_pad: 0, source_stream: 0 [ 55.666206] num_entries: 0, w*h: 32 * 192, code: 0x3008, bpp: 16 [ 55.666212] num_routes: 4, source_pad: 0, source_stream: 1 [ 55.666216] num_entries: 1, w*h: 480 * 128, code: 0x3008, bpp: 16 [ 55.666221] num_routes: 4, source_pad: 0, source_stream: 2 [ 55.666225] num_entries: 2, w*h: 40 * 1, code: 0x3001, bpp: 8 [ 55.666230] num_routes: 4, source_pad: 0, source_stream: 3 [ 55.666235] num_entries: 3, w*h: 40 * 1, code: 0x3001, bpp: 8 [ 55.666993] --on:1, dbg_ctrl:0x8, load_script: 0, ROI_data_src: 0 (from Nor_flash), lens_type: 0 (WIDEANGLE), workMode:6 (PCM), linkFreq:500000000, hawk_eco_version:Unknown, is_early_chip: 0, prbs_seed:0x2e, mcu_chipid:0, mcu_fw_type: 0x0, drv_version: 3.2.0_LM20240904a--- [ 55.667520] client: hawk_concurrenc (951:951) is running on CPU 0, ctrl->id: 0x9f0901, ctrl->val: 1, V4L2_CID_EXPOSURE: 0x980911 [ 55.667530] sensor_set_ctrl Unhandled id:0x9f0901, val:0x1 [ 55.667536] client: hawk_concurrenc (951:951) is running on CPU 0, ctrl->id: 0x980911, ctrl->val: 100, V4L2_CID_EXPOSURE: 0x980911 [ 55.667543] use roi sram from camxhawk-roi-mem.h, workMode: PCM, roi_data: 000000009fa58e36, roi sram length: 6976 [ 55.673503] client: hawk_concurrenc (951:951) is running on CPU 0, pad: 0, name:m00_dToF_ads6311 spi1.0, fd: 000000003963de67 [ 55.673518] num_routes: 4, source_pad: 0, source_stream: 0 [ 55.673523] num_entries: 0, w*h: 32 * 192, code: 0x3008, bpp: 16 [ 55.673528] num_routes: 4, source_pad: 0, source_stream: 1 [ 55.673532] num_entries: 1, w*h: 480 * 128, code: 0x3008, bpp: 16 [ 55.673537] num_routes: 4, source_pad: 0, source_stream: 2 [ 55.673542] num_entries: 2, w*h: 40 * 1, code: 0x3001, bpp: 8 [ 55.673546] num_routes: 4, source_pad: 0, source_stream: 3 [ 55.673551] num_entries: 3, w*h: 40 * 1, code: 0x3001, bpp: 8 [ 55.673662] client: hawk_concurrenc (951:951) is running on CPU 0, pad: 0, name:m00_dToF_ads6311 spi1.0, fd: 000000003963de67 [ 55.673671] num_routes: 4, source_pad: 0, source_stream: 0 [ 55.673675] num_entries: 0, w*h: 32 * 192, code: 0x3008, bpp: 16 [ 55.673680] num_routes: 4, source_pad: 0, source_stream: 1 [ 55.673684] num_entries: 1, w*h: 480 * 128, code: 0x3008, bpp: 16 [ 55.673689] num_routes: 4, source_pad: 0, source_stream: 2 [ 55.673693] num_entries: 2, w*h: 40 * 1, code: 0x3001, bpp: 8 [ 55.673698] num_routes: 4, source_pad: 0, source_stream: 3 [ 55.673702] num_entries: 3, w*h: 40 * 1, code: 0x3001, bpp: 8 [ 55.673773] client: hawk_concurrenc (951:951) is running on CPU 0, pad: 0, name:m00_dToF_ads6311 spi1.0, fd: 000000003963de67 [ 55.673781] num_routes: 4, source_pad: 0, source_stream: 0 [ 55.673785] num_entries: 0, w*h: 32 * 192, code: 0x3008, bpp: 16 [ 55.673790] num_routes: 4, source_pad: 0, source_stream: 1 [ 55.673794] num_entries: 1, w*h: 480 * 128, code: 0x3008, bpp: 16 [ 55.673799] num_routes: 4, source_pad: 0, source_stream: 2 [ 55.673802] num_entries: 2, w*h: 40 * 1, code: 0x3001, bpp: 8 [ 55.673807] num_routes: 4, source_pad: 0, source_stream: 3 [ 55.673811] num_entries: 3, w*h: 40 * 1, code: 0x3001, bpp: 8 [ 57.021528] ti-udma 4e230000.dma-controller: chan0 teardown timeout! [ 58.045514] ti-udma 4e230000.dma-controller: chan1 teardown timeout! [ 58.047618] --on:0, dbg_ctrl:0x8, load_script: 0, ROI_data_src: 2 (from builtin_dot_h_file), lens_type: 0 (WIDEANGLE), workMode:6 (PCM), linkFreq:500000000, hawk_eco_version:Unknown, is_early_chip: 0, prbs_seed:0x2e, mcu_chipid:0, mcu_fw_type: 0x0, drv_version: 3.2.0_LM20240904a---

Hello Xiangxu,
Thanks for reporting this issue. We will be investigating it.
Meanwhile, the best practices for building an image processing pipeline usually avoid memory copy by the CPU. Even though setting ASEL to 15 can speed up memcpy, it has some side effects, as explained in this FAQ: Why is memcpy so slow on AM6x when copying data from a V4L2 buffer? Therefore the best solution for you case may be to optimize your system such that memcpy is avoided.
Regards,
Jianzhong
Hi Xiangxu,
I just checked with the HW team and found out that ASEL=14 or 15 is not supported on AM62P. So you'll have to optimize your application to avoid using memcpy.
Regards,
Jianzhong
hi jianzhong:
So what else can you do to improve dma speed?
Is there a memory consistency buffer specified by hardware when dma request buffer is supported? Now our application scenario requires frequent operations based on the raw data in the buffer after dma is moved
At the same time, when ASEL=14 or 15 is not turned on, we count the dma abnormal frame rate flag in the dma callback and find that there will be a dma error frameproblem
j721e-csi2rx.c file
static void ti_csi2rx_dma_callback(void *param,
const struct dmaengine_result *result)
{
struct ti_csi2rx_buffer *buf = param;
struct ti_csi2rx_ctx *ctx = buf->ctx;
struct ti_csi2rx_dma *dma = &ctx->dma;
unsigned long flags = 0;
/*
* TODO: Derive the sequence number from the CSI2RX frame number
* hardware monitor registers.
*/
buf->vb.vb2_buf.timestamp = ktime_get_ns();
buf->vb.sequence = ctx->sequence++;
spin_lock_irqsave(&dma->lock, flags);
WARN_ON(!list_is_first(&buf->list, &dma->submitted));
if (0 == (ctx->ok_frame_cnt + ctx->ng_frame_cnt))
{
ctx->rx_start = ktime_get();
}
if (result && (result->result != DMA_TRANS_NOERROR || result->residue != 0))
{
#if 0 // The log may bring something can't restored unless reboot the system, according to Qingfeng's test.
dev_err(ctx->csi->dev, "Failed DMA transfer for frame#%u of (stream: %d idx: %d, vc: %d),timestamp: %lld result=%d, residue=%u\n",
buf->vb.sequence, ctx->stream, ctx->idx, ctx->vc, buf->vb.vb2_buf.timestamp, result->result, result->residue
);
#endif
ctx->ng_frame_cnt++;
vb2_buffer_done(&buf->vb.vb2_buf, VB2_BUF_STATE_ERROR);
} else {
ctx->ok_frame_cnt++;
vb2_buffer_done(&buf->vb.vb2_buf, VB2_BUF_STATE_DONE);
}
list_del(&buf->list);
ti_csi2rx_dma_submit_pending(ctx);
if (list_empty(&dma->submitted))
dma->state = TI_CSI2RX_DMA_IDLE;
spin_unlock_irqrestore(&dma->lock, flags);
}root@am62pxx-evm:/run/media/data-mmcblk0p5/output/bin# cat /sys/devices/platform/bus@f0000/30102000.ticsi2rx/csi_rx_status stream[0] ok: 352, ng: 2, total_fps: 1, ok_fps: 1 stream[1] ok: 278, ng: 78, total_fps: 1, ok_fps: 1 stream[2] ok: 353, ng: 0, total_fps: 1, ok_fps: 1 stream[3] ok: 355, ng: 0, total_fps: 1, ok_fps: 1
So what else can you do to improve dma speed?
It's not the DMA speed that needs to be improved. You're doing memcpy through CPU, which is slow due to cache maintenance, as explained in the FAQ mentioned earlier.
You'll need to optimize your application to avoid memcpy. For example, if you use the Gstreamer framework to stream from the camera to a display, there will be zero memcpy.
At the same time, when ASEL=14 or 15 is not turned on, we count the dma abnormal frame rate flag in the dma callback and find that there will be a dma error frameproblem
I assume this happened when you had the memcpy of 3932160 bytes. Can you test if you still see the DMA error if you don't do the memcpy?
Thank you.
Jianzhong
I assume this happened when you had the memcpy of 3932160 bytes. Can you test if you still see the DMA error if you don't do the memcpy?
Thank you.
don't quite understand the logic, but stopping the copy means that the output of the stream is cut off。the probability will occur in the middle of this frame error, error can continue to flow
Can you try something like "v4l2-ctl --stream-mmap" and see if it can operate at the sensor frame rate? That should rule out any issue with the CSI Rx driver (including DMA).
As per today's discussion, we align that below is the customer setup and issue is faced during data transfer between 2 memory location in DDR (DDR_M1 to DDR_M2 ).
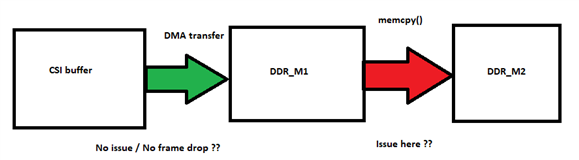
Customer reported issue is that data transfer between DDR_M1 to DDR_M2 is slow.
Expetced data transfer rate is (40-80M) per 30ms.
Next Steps:
Regards
Ashwani
Thanks Freddy, As per discussion in followup meeting, here is the customer setup:
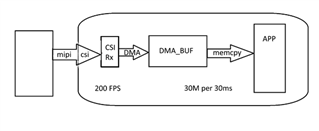
Some points to consider on customer side:
Regards
Ashwani
Hi Xiangxu,
To speed up memcpy and buffer exchanges, please enable software based in-kernel cache maintenance operations by making necessary changes in kernel and user-space application as shared in below steps :
1) Apply attached patch /cfs-file/__key/communityserver-discussions-components-files/791/0001_2D00_media_2D00_ti_2D00_j721e_2D00_csi2rx_2D00_Allow_2D00_passing_2D00_cache_2D00_hints_2D00_from.patch to ti-linux-kernel which enables passing cache hints from user-space.
2) Make below changes in your v4l2 user-space application :
i) Pass V4L2_MEMORY_FLAG_NON_COHERENT while requesting buffers (VIDIOC_REQBUFS) from v4l2 as shared in below snippet:
rb.count = nbufs;
rb.type = dev->type;
rb.memory = dev->memtype;
+ rb.flags = V4L2_MEMORY_FLAG_NON_COHERENT;
ret = ioctl(dev->fd, VIDIOC_REQBUFS, &rb);
if (ret < 0) {
ii) Pass V4L2_BUF_FLAG_NO_CACHE_CLEAN while en-queuing buffers (VIDIOC_QBUF) from v4l2 as shared in below snippet:
buf.index = index;
buf.type = dev->type;
buf.memory = dev->memtype;
buf.flags = V4L2_BUF_FLAG_NO_CACHE_CLEAN;
ret = ioctl(dev->fd, VIDIOC_QBUF, &buf);
You may refer attached patch /cfs-file/__key/communityserver-discussions-components-files/791/0001_2D00_yavta_2D00_hack_2D00_Pass_2D00_cache_2D00_hints_2D00_from_2D00_user_2D00_space_2D00_for_2D00_capt.patch while making above changes.
3) To summarize the observations, we basically see a 5x improvement in memcpy time with suggested changes as shared below :
i) Original average time to copy 614400 bytes was 5.193 ms :
yavta -c200 -F/run/capture -s 640x480 -f UYVY /dev/video2 > /run/1.txt tail /run/1.txt | grep avg avg: 0.005193
With above changes, time to copy 614400 bytes reduced to 1.085 ms :
yavta -c200 -F/run/capture -s 640x480 -f UYVY /dev/video2 > /run/2.txt tail /run/2.txt | grep avg avg: 0.001085
Kindly let us know if any issues faced.
Regards
Devarsh



