


Hello, how are you?
I want to ask you a question. We are working on a design of LMK04832-SP in dual loop mode.We made some tests about that mode and we noticed the PLL2 single loop mode has a better performance than dual loop mode. We are working with PLLatinum, we made all our test in PLLatinum, dual mode and single mode, and we can simulate the PLL2 single loop performance from the datasheet with PLLatinum. See the figures below.
-------------------------------------------------------------------------------------------------------------------------
Simulate datasheet performance at 3200Mhz pll2 single mode
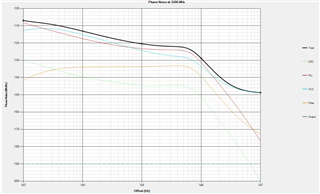
-------------------------------------------------------------------------------------------------------------------
Dual modo perfomance at 1600Mhz
In my Dual mode case, we have a XO of 100Mhz in the input of PLL1, the input of PLL2 is the output of PLL1.
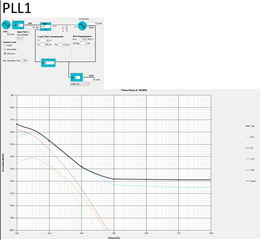

-------------------------------------------------------------------------------------------------------------------
PLL2 Single modo perfomance at 1600Mhz
In my PLL2 single mode case I have a XO of 100Mhz in the input of PLL2.
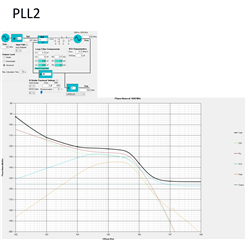
-------------------------------------------------------------------------------------------------------------------
We've read in the datasheet that the dual loop PLL architecture should provide the lowest jitter performance, but based on our simulations we are obtaining the opposite results.
Do you know why is that? We want to understand why the Single mode performance is better than dual mode.
Best.
Facundo Cosentino
