Other Parts Discussed in Thread: TMS320C6416T
Hi Champs:
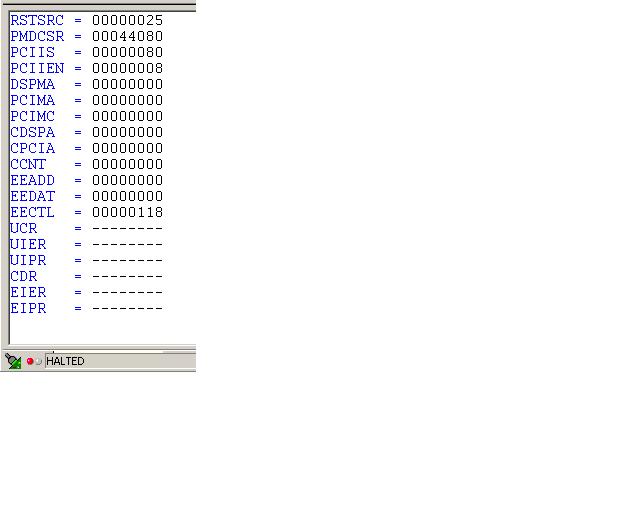
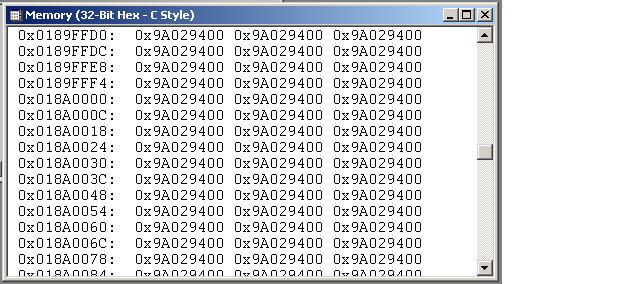
My customer is having an intermittent PCI issue on 6416. Please see the attached doc file for more information on data being captured.. This is an intermittent problem, and out test (software and hardware) seem to work correctly most of the time.
This attached doc describes a failure condition we see while trying to write to the DSP Internal RAM memory across the PCI bus. We have only the processor and DSP on the PCI bus.
Thanks for your help.
Pradhyum